Hugo Proença, Senior Member, IEEE and João C. Neves
Abstract: This work describes a classification strategy that can be regarded as a more general form of nearest-neighbour classification. It fuses the concepts of \emph{nearest neighbours}, \emph{linear discriminant} and \emph{Vantage-Point} tree, yielding an efficient indexing data structure and classification algorithm. In the learning phase, we define a set of disjoint subspaces of reduced complexity that can be separated by linear discriminants, ending up with an ensemble of simple (weak) classifiers. In classification, the closest centroids to the query determine the set of classifiers considered. The algorithm was experimentally validated in datasets widely used in the field, attaining error rates that are favourably comparable to the state-of-the-art classification techniques. Lastly, the proposed algorithm has a set of interesting properties for a broad range of applications: 1) it is deterministic; 2) it classifies in time approximately logarithmic with respect to the size of the learning set, being far more efficient than nearest neighbour classification in terms of computational cost; and 3) it keeps the generalisation ability of simple models.
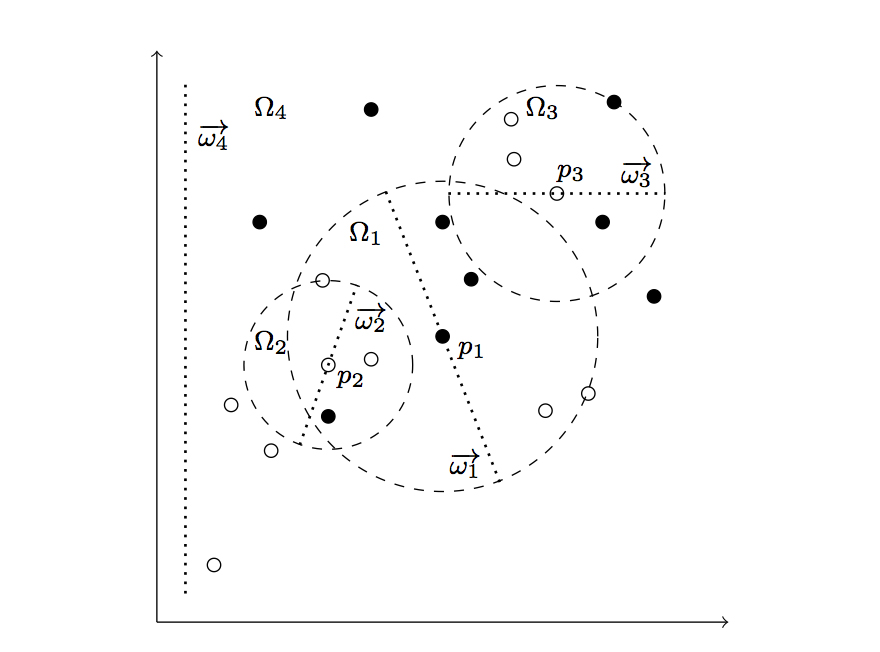
Fig. 1: Illustration of the Vantage Point Classification scheme, using linear discriminant analysis in leaves. Dotted line segments denote the projections ωi found for compact spaces Ωi and dashed circles denote the median L2 distance between pivots pi and elements on that node. This value is used to separate elements at each side of the vantage point tree.
Source Code
Abstract: This work describes a classification strategy that can be regarded as a more general form of nearest-neighbour classification. It fuses the concepts of \emph{nearest neighbours}, \emph{linear discriminant} and \emph{Vantage-Point} tree, yielding an efficient indexing data structure and classification algorithm. In the learning phase, we define a set of disjoint subspaces of reduced complexity that can be separated by linear discriminants, ending up with an ensemble of simple (weak) classifiers. In classification, the closest centroids to the query determine the set of classifiers considered. The algorithm was experimentally validated in datasets widely used in the field, attaining error rates that are favourably comparable to the state-of-the-art classification techniques. Lastly, the proposed algorithm has a set of interesting properties for a broad range of applications: 1) it is deterministic; 2) it classifies in time approximately logarithmic with respect to the size of the learning set, being far more efficient than nearest neighbour classification in terms of computational cost; and 3) it keeps the generalisation ability of simple models.
Fig. 1: Illustration of the Vantage Point Classification scheme, using linear discriminant analysis in leaves. Dotted line segments denote the projections ωi found for compact spaces Ωi and dashed circles denote the median L2 distance between pivots pi and elements on that node. This value is used to separate elements at each side of the vantage point tree.
Source Code
- [DOWNLOAD] (Contains
the source code, in C++ format, together with auxiliary functions to
export data sets from MATLAB and example data sets). This code is
released under the GPL license.