O que é o shell
Perfil do login (.profile)
Procedimentos shell
Alguns procedimentos shell simples
Dar nome a procedimentos shell
Variáveis Shell
Variáveis de Shell predefinidas
Modificar a prompt do sistema UNIX
Atribuição de uma variável através
do output de um comando
Argumentos para procedimentos shell
O comando echo revisto
Programação em Shell
Estrutura repetitiva com o comando for
Estrutura condicional com o comando if
O comando exit
O uso de else, no comando if e o comando
elif
O comando test
Testes a valores numéricos
Testes a tipos de ficheiros
Testes a cadeias de caracteres
Combinação de testes: os operadores
-a e -o
Combinação de comandos if e for
Estrutura repetitiva com o comando while
Alterar a execução dos ciclos: comandos
break e continue
O comando until
Os comandos true e false
Execução selectiva, usando o comando
case
Utilização do espaço /tmp
Comentários em procedimentos shell
Manipulação de interrupts
Cálculo aritmético com o comando expr
Here documents
Entrada de dados do utilizador
Passagem do standard input
Procedimentos interactivos com o comando read
Funções shell
Depuração de procedimentos shell
Conclusão
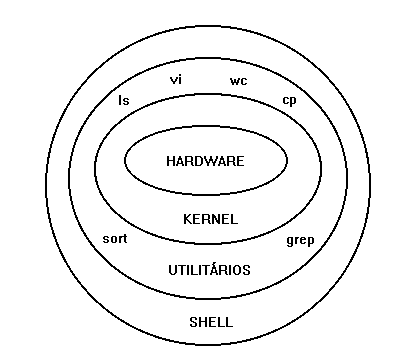
Com base no diagrama seguinte vamos analizar o que o shell representa:
Diagrama do shell
No centro encontra-se o computador e equipamento associado; discos, dispositivos de armazenamento, impressoras, etc. A este conjunto de dispositivos designamos hardware do sistema.
Envolvendo o hardware existem alguns programas que tratam os detalhes de diálogo com a memória e com os periféricos de armazenamento, realizando a gestão de recursos do computador, efectuando a organização do sistema de ficheiros. Todo este trabalho atribuído ao sistema operativo permite libertar os utilizadores para tarefas mais criativas e que envolvam o que este deseja verdadeiramente fazer. Ao nível (camada) do software que cuida dos pormenores de lidar com o hardware designamos por kernel. O UNIX possui um kernel.
O kernel proporciona a camada de suporte, independente do hardware, para os programas utilitários como o "sort", o "grep", o editor de texto "vi" e vários compiladores como o "cc" (para a linguagem C). Estes utilitários constituem a camada seguinte à do kernel.
A camada mais exterior representa o shell. O shell forma o interface entre os utilizadores e o resto do sistema, de facto, o esquema apresentado, é apenas uma visão aproximada, uma vez que o shell está representado por uma camada própria a rodear o sistema. Na realidade um dos grandes trunfos do UNIX é que a shell não possui nenhumas características especiais em relação a outros comandos e por isso mesmo é considerado mais um utilitário.
A shell constitui apenas um programa utilitário que acompanha o UNIX. É possível substituir o standard shell, "sh", por um outro, existindo uma variedade de shells para o efeito. Exemplo são o C shell, "csh", o B shell e o Korn shell. O shell original, objecto do nosso estudo, é o Bourne shell.
O shell é um programa que corre automaticamente quando se executa o "login" (entrada no sistema) do UNIX. Este lê cada comando introduzido no terminal e interpreta o seu pedido. O shell expande todos os caracteres especiais utilizados. Se for redireccionado o standard output e standard input ou o output de diagnóstico, o shell trata e assegura o seu correcto funcionamento.
Finalmente o shell examina o comando introduzido, chama o programa correspondente do local apropriado (lembrar que os comandos podem estar em mais de um local como /bin e /usr/bin) e então passa-os para o programa e executa-o.
Embora tivessemos referido o shell como uma camada exterior separada, no diagrama anterior, o próprio shell é apenas um programa normal que pode ser chamado pelo comando "sh".
O argumento dado a "sh" é o nome do ficheiro que contém comandos válidos do sistema UNIX. Podem ainda ser utilizadas facilidades do shell que tornam este, semelhante a uma linguagem de programação, tais como:
Estas facilidades proporcionam a construção de utilitários próprios (assunto focado neste texto). s ficheiros de comandos são designados "procedimentos shell", "ficheiros shell" ou, ainda, "shell scripts".
Graças ao facto de o Shell ser apenas um programa, chamado para interpretar comandos dados pelo utilizador e não parte integral do kernel, é possível correr diferentes versões do Shell. Neste texto é descrita apenas a versão standard no sistema UNIX versão V, designada por Bourne shell em homenagem ao seu criador S. R. Bourne dos Laboratórios Bell.
Quando um utilizador entra no sistema UNIX (login), o Shell é chamado de modo a servir de interface com o utilizador; sessão. A primeira acção que o Shell executa é verificar e interpretar o conteúdo do ficheiro de perfil do utilizador. O ficheiro é designado por ".profile" e encontra-se localizado no directório "home" correspondente ao utilizador em causa. Se o ficheiro ".profile" existir, então todos os comandos que contem são executados pelo Shell antes de ser passado o controlo ao utilizador (visualização da "prompt" do sistema).
Assim se existirem tarefas que o utilizador execute sempre no início da sua sessão então deve ser criado o ficheiro de perfil e lá colocados todos os comandos necessários.
Um bom exemplo é a definição do terminal utilizado e das teclas de edição utilizadas. Assim podemos usar o comando stty para adaptação do nosso terminal. Colocando o comando com os valores adequados no ficheiro de perfil ".profile" evitamos fazer a sua declaração cada vez que efectuamos o login.
É possível colocar qualquer comando do sistema Unix que se pretenda no ficheiro de perfil; assim que efectuar a entrada no sistema pode querer saber a data do sistema, quem se encontra a utilizar o sistema, definir algumas das funções do terminal e obter as notícias mais recentes, pelo que o ficheiro .profile teria o seguinte aspecto:
stty erase '^H' kill '^U'
who
news -n
date
Outra acção normal a realizar no ficheiro de perfil é a mudança da prompt do simbolo normal da prompt do UNIX; "$". A prompt é definida por uma variável da Shell e é possível modifica-la, atribuindo-lhe outro valor, o que a torna a diferente.
Outra variável da Shell informa o sistema onde procurar pelos comandos. Usualmente são os directórios /bin e /usr/bin, os locais de pesquisa, mas se for pretendida a criação de área própria para comandos privados, é possível indicar ao sistema os directórios onde estes se encontram. Estas atribuições devem estar também no ficheiro de perfil.
Um procedimento shell é um ficheiro que contém comandos. Se possuirmos um ficheiro destes que denominamos "paula" com um conjunto de comandos do sistema UNIX, existem dois modos diferentes de executar os comandos contidos no ficheiro. O primeiro é colocando o nome do ficheiro como argumento do comando "sh":
$ sh paula
A segunda forma é usar o comando "chmod" para modificar as permissões do ficheiro de modo a torná-lo executável. Para executar esta operação, o que realmente se está a fazer é construir mais um utilitário ou próprio comando:
$ chmod 755 paula
$ paula
O comando "chmod" torna o ficheiro executável (permissões rwxr-xr-x) - o ficheiro shell criado pode ser executado como qualquer outro comando do UNIX.
É necessário ter cuidado com a forma de dar nome aos ficheiros de comandos próprios: se se duplicar o nome de um comando existente (um que esteja em /bin ou /usr/bin), perde-se acesso ao comando original e pode apenas aceder ao criado com o mesmo nome. Para se aceder ao comando original é necessário indicar, além do nome, o caminho onde este se encontra, o que não é muito prático.
Um procedimento shell extremamente simples pode ser realizado recorrendo ao comando "echo". O comando "echo" escreve os seus argumentos no standard output. O procedimento inicial a criar permitir felicitar o utilizador:
$ cat > felicitar
echo Ola, tudo bom!
^D
$ chmod 755 felicitar
$
Foi criado o ficheiro shell designado felicitar e tornado executável. Se agora se escrever o comando felicitar obtêm-se:
$ felicitar
Ola, tudo bom!
$
Se se pretender que o sistema UNIX dê esta mensagem sempre que se entre no sistema então deve-se colocar o comando felicitar no ficheiro de perfil.
Analise-se um exemplo mais útil. Utilizando os comandos utilitários de manipulação de texto e tomando um ficheiro que contenha uma lista de pessoas e os respectivos números telefónicos, vamos utilizar este ficheiro para imprimir uma lista de distribuição, com cabeçalho, ordenada e sem números telefónicos, para a impressora. Para o efeito utiliza-se o seguinte encadeamento de comandos:
$ sort +1 -2 pessoas | tr -d "[0-9]" | pr -h distribuicao
| lp
$
Este é, sem dúvida, um longo comando para escrever e fácilmente se pode errar a sua introdução. Igualmente, se a lista de distribuição for raramente necessária, é fácil esquecer o conteúdo da linha de comandos para a obter. A solução para ambos os problemas enunciados é a criação de um ficheiro shell:
$ cat > lista
sort +1 -2 pessoas | tr -d "[0-9]" | pr -h distribuicao | lp
^D
$
e tornar este executável, com o comando "chmod":
$ chmod 755 lista
$
Agora é possível obter a lista invocando simplesmente o comando:
$ lista
$
Não existe nenhuma resposta além da prompt do sistema porque o output foi direccionado para a impressora pelo próprio ficheiro shell. Se for pretendida a verificação do output do comando lista antes de ser impresso, deve-se retirar o comando final "lp" do final da linha de comandos encadeados (pipe):
$ cat > lista
sort +1 -2 pessoas | tr -d "[0-9]" | pr -h distribuicao
^D
$ chmod 755 lista
O output desta versão do comando "lista" aparece no ecrân do terminal. Para enviar o output para a impressora é necessário utilizar o comando em pipeline:
$ lista | lp
$
Examinemos um procedimento shell mais complexo que ilustre o uso efectivo da Shell e demonstre alguns dos potenciais perigos que se podem correr. Suponhamos que sempre que se utilize o comando "ls" se pretenda a utilização das opções -x e -F para obter uma listagem a várias colunas com a marcação dos ficheiros que são directórios e executáveis. Para não escrever sempre "ls -x -F", escreve-se um ficheiro shell designado ld (listagem de directórios).
$ cat > ld
ls -x -F
^D
$ chmod 755 ld
$ ld
texto ld* docs/ pessoas util*
progs/ prog1* enuncp1
O comando funciona, mas suponhamos que o hábito de usar o comando "ls" é tão forte que se esquece a existência do comando "ld" até que se escreve ls. Podemos ser tentados a fazer uma cópia do ficheiro ld para um novo comando designado ls:
$ cp ld ls
$ ls
Agora possuimos uma versão própria do comando "ls", mas quando se tenta usar o sistema não dá resposta! é necessário interromper o comando (com uso da tecla break ou CTRL-C) de modo a voltarmos à prompt. A razão para esta situação é devida a tentarmos chamar o comando ls do nosso comando ls (chamando-se a si mesmo) o que por sua vez invocava novamente o comando ls e assim sucessivamente, entrando em ciclo.
O modo de contornar este problema é utilizar a indicação completa de identificação do verdadeiro comando ls:
$ cat > ls
/bin/ls -x -F
^D
$
e tornando o comando executável usando chmod:
$ chmod 755 ls
$ ls
texto ld* docs/ pessoas util*
progs/ prog1* enuncp1
$
O exemplo descrito demonstra o cuidado a ter quando se designam os ficheiros de comandos shell, especialmente quando se tratam de versões modificadas de comandos existentes.
Até ao momento, apenas se utilizou a nova versão do comando "ls" para o directório corrente, verifiquemos o que acontece se se utilizar num outro directório:
$ ls /etc
texto ld* docs/ pessoas util*
pogs/ prog1* enuncp1
$
Continuamos a obter uma listagem do directório corrente, porque a nossa versão do comando ls ignora qualquer argumento indicado. Oportunamente será referida a forma como os procedimentos shell podem reconhecer os argumentos dados na linha de comando.
Entretanto, pode-se contornar o problema, mudando de directório antes de usar a versão especial do comando "ls":
$ cd /usr
$ ls
bin
games
dict
include
mail
man
sigrup1
sigrup2
sigrup3
$
Agora voltamos a usar a versão do sistema do comando ls. Se se tentar usar a primeira originalmente desenvolvida obtemos piores resultados:
$ cd /usr
$ ld
ld: not found
$
O sistema nem sequer reconhece o comando. Tal acontece porque o Shell procura os comandos em vários directórios numa ordem fixa; a ordem de defeito é a seguinte:
Se o comando não se encontrar em nenhum destes directórios, obtêm-se a mensagem de erro "not found", mas se não existir permissão para o comando fornecido, então obtêm-se uma mensagem diferente - "cannot execute". O sistema executa (ou tenta executar) a primeira versão do comando que encontrar, pelo que se o comando existir em ambos os directórios de sistema /bin e /usr/bin, é a versão no directório /bin que é tomada. Esta é a razão pela qual se pode possuir um comando com o mesmo nome dos comandos no /bin e os próprios terem procedência (quando residentes no directório corrente).
No entanto, se o nome do comando introduzido contiver o caminho ou local onde se encontra, (inclui a indicação dos directórios a partir da raiz /), resulta que o sistema já não procura nos diversos directórios e usa o comando especificado pelo nome completo. Assim podemos fazer:
$ cd /usr
$ /aa/sigrup2/luis/ld
bin/ games/ dict/ include/
mail/ man/ sigrup1/ sigrup2/
sigrup3/
$
Os directórios onde o sistema procura os comandos e a ordem em que o faz, designa-se por caminho de busca de comandos ou "path". Este caminho de busca é função de uma variável de sistema que pode ser alterada. Pode-se assim designar um directório do utilizador como fazendo parte das buscas de comandos, alterando o valor da variável em causa. Se se utilizar o mesmo padrão de buscas de comandos em todas as sessões do utilizador no sistema, pode-se incluir a atribuição de novo valor da variável no ficheiro de perfil.
Primeiro deve-se criar um directório que inclua os nossos novos comandos:
$ mkdir bin
$ mv ld ls bin
$
Se utilizarmos o comando ls:
$ ls
bin
texto
docs
pessoas
util
progs
prog1
enuncp1
$ ls bin
ld
ls
$
verificamos que os ficheiros ld e ls foram movidos para o directório criado bin, tornando a usar o comando ls do sistema porque ainda não se alterou a variável de sistema path para pesquisar o directório privado de comandos do utilizador.
Repare que o comando ls produziu um output que inclui a referência ao directório bin. Este directório é o local onde estão contidos os comandos criados pelo utilizador; trata-se de uma prática normal e consistente com a nomenclatura usada pelo próprio sistema UNIX. No entanto não é necessário designar o directório por bin; poder-se-iam usar outras designações que o utilizador pretendesse.
No próximo ponto serão discutidas as variáveis da Shell, em que se mostra a forma como alterar o caminho de pesquisa de comandos de forma a incluir os comandos criados pelo utilizador.
A Shell possui a capacidade de definição de variáveis e de realizar operações de atribuição com estas. O modo mais simples de o fazer é através de uma linha de atribuição:
variavel=valor
O valor atribuído à variável pode ser recuperado precedendo o nome da variável com o simbolo do dollar - $:
$variavel
Por exemplo, verifique-se o que acontece com o uso destes comandos:
$ fruta=maca
$ queijo=serra
$ vinho=dao
$ echo $fruta, $queijo, $vinho ...Mmmm!
Maca, serra, dao ...Mmmm!
$
O valor atribuído à variável pode ser definido usando outra ou outras variáveis shell, ou mesmo por atribuição da própria variável:
$ vinho=$fruta-assada
$ fruta=grande$fruta
$ echo $vinho e $fruta
maca-assada e grandemaca
$
Se for pretendido "maca-assada" sem o hifen, não era possível fazer a atribuição com a linha vinho=$fruta-assada. A Shell iria procurar uma variável chamada "frutaassada", que não existe. O resultado era a atribuição a $vinho do valor nulo (null) ou cadeia vazia. Se realmente é pretendido o valor "macaassada" definido por invocação da variável $fruta. Neste caso é necessário delimitar a variável com chavetas:
$ fruta=maca
$ vinho=${fruta}assada
$ echo $vinho
macaassada
$
As chavetas deverão ser utilizadas sempre que a variável tiver que ser combinada com outra string ou cadeia de caracteres, e não existe outro modo do fim do nome da variável e o início da string que se lhe segue.
Embora o uso das variáveis da Shell seja mais comum dentro dos procedimentos shell, também podem ser usadas em modo interactivo. São usadas em modo interactivo sempre que se pretenda utilizar uma notação abreviada dos comandos ou sequências de comandos mais comuns. Por exemplo, suponhamos que existe um directório com um longo caminho ou nome completo que usamos frequentemente. Podemos, neste caso, constituir uma variável de Shell local para o caminho e, a partir daí, aceder a ficheiros nesse directório por $local/ficheiro. Esta pratica pode poupar bastante tempo e evitar que se tenha de corrigir erros de tipografia quando se utiliza o nome completo.
Um outro exemplo é o recurso a variáveis Shell sempre que se utilizar um comando com argumentos para diferentes tarefas:
$ s="sort +2n +1 -2"
$ $s tenis | lp
$ $s futebol | lp
$ $s squash | lp
$ $s pingpong | lp
Repare que o uso de aspas (") preserva os espaços na definição da variável. Se se utilizar uma variável da Shell como abreviatura de uma linha de comando, devemos verificar se esta não contem simbolos de pipe (|), redireccionamento (< ou >), ou o símbolo de processamento em background (&).
O Shell atribui valores de defeito a algumas variáveis. Algumas das variáveis predefinidas podem ser modificadas. Outras são apenas de leitura, isto é, podem ser usadas mas não modificadas. As variáveis predefinidas mais comuns são:
HOME
é-lhe atribuido o valor do directório base do utilizador, funciona como argumento de defeito ao comando "cd".
PATH
possui o conjunto de directórios que o sistema pesquisa para a procura de comandos indicados.
PS1
trata-se da string de prompt primária. É o indicativo de presença do sistema, no UNIX, é o simbolo dollar ($).
Com base nas variáveis predefinidas é possível modificar ou realizar tarefas que foram já objecto de estudo neste texto; utilização da variável HOME e PATH.
O prompt do sistema pode ser modificado pela redefinição da variável de Shell que contem o caracter ou caracteres de prompt. Se for pretendida uma prompt razoavelmente simples, pode ser incluido no ficheiro de perfil a linha:
PS1=?
Agora, em vez do usual simbolo $ a prompt é constituida pelo simbolo ?. É necessário ter cuidado com a escolha de nova prompt, alguns comandos interactivos (como o mail) também possuem o simbolo ? como prompt o que poderá levar a alguma confusão.
Na prática, qualquer que seja o prompt escolhido, é considerado que um espaço adicionada à prompt escolhida facilita a sua utilização. Para assegurar a atribuição do espaço deve colocar aspas:
PS1="? "
As aspas são também necessárias quando se pretende uma prompt mais elaborada:
PS1="Que queres tu! "
Se pretender usar sempre esta prompt deve colocar a respectiva linha de comando no ficheiro de perfil - ".profile".
A ordem normal de pesquisa que o sistema utiliza para procurar nos directórios os comandos é: o directório corrente, depois o directório /bin, e finalmente o directório /usr/bin. A variável de caminho de busca é designada PATH:
$ echo $PATH
:/bin:/usr/bin
$
Os nomes completos dos diferentes directórios que são pesquisados estão separados por dois pontos (:), com o directório corrente designado pelos dois pontos iniciais.
Se pretender que o sistema procure os comandos no próprio directório privado de comandos (já anteriormente designado bin), simplesmente se muda o valor da variável Shell PATH.
$ echo $HOME
/aa/sigrup2/luis
$ PATH=:$HOME/bin$PATH
$ echo $PATH
:/aa/sigrup2/luis/bin:/bin:/usr/bin
para colocar o directório do utilizador entre o directório corrente e bin. Este é a ordem de busca mais comum, mas se se possuir diferentes necessidades então pode-se escolher livremente outra ordem para a colocação dos directórios de busca.
O comando para definir a sequência de pesquisa deve ser colocado no ficheiro de perfil, caso contrário é necessário proceder à sua definição cada vez que se iniciar uma sessão no sistema.
Pode-se atribuir a uma variável o output de um comando:
$ agora=`date`
$ echo $agora
Sat Jan 4 16:43:28 POR 1992
Os caracteres envolvendo o comando no exemplo mostrado são o acento grave (`); este caractere é diferente do apóstrofe.
Se se pretender a atribuir a uma variável o valor contido num ficheiro, podemos fazer:
menu=`cat comida`
Se o ficheiro comida tem o seguinte conteúdo:
macas
serra
dao
o valor resultante da variável menu é:
$ echo $menu
macas serra dao
$
Como é dado verificar pelo exemplo, os caracteres de nova linha são transformados em espaços.
Existe um tipo diferente de variável Shell que se destina a passar valores para um procedimento shell quando este é invocado com argumentos; trata-se do argumentos de procedimento. Estes são chamados usualmente de argumentos posicionais, devido ao seu acesso ser feito pelo número da sua posição na lista de argumentos. Por exemplo, se tivermos um procedimento chamado pelo comando:
$ exper uvas macas peras
Então "uvas", "macas" e "peras" são parâmetros posicionais ou de posição e são acedidos por $1, $2 e $3 respectivamente.
Se o comando é chamado:
$ exper serra flamengo ingles
então $1 é "serra", $2 é "flamengo" e $3 é "ingles".
Um simples exemplo de utilização é dado pelo seguinte procedimento shell:
$ cat reverte
echo $5 $4 $3 $2 $1
$
Este procedimento toma os primeiros cinco argumentos e envia-os para o standard output na ordem inversa:
$ reverte pem pim pam pum mataum
mataum pum pam pim pem
$
Se o procedimento é chamado com menos de cinco argumentos:
$ reverte tic tac toe
toe tac tic
$
strings vazias (nulas) substituem os argumentos em falta. Se o procedimento for chamado com mais de cinco argumentos, apenas os cinco primeiros são tomados, ignorando-se os excedentes.
Um exemplo onde os cinco argumentos são necessários é no procedimento lista, já apresentado.
$ cat lista
sort +1 -2 pessoas | tr -d "[0-9]" | pr -h distribuicao | lp
$
O procedimento funciona para o ficheiro pessoas. Se se colocar $1 no lugar de pessoas, podemos usar o procedimento para mais de um ficheiro.
$ cat lista
sort +1 -2 $1 | tr -d "[0-9]" | pr -h distribuicao | lp
$ lista tecnicos
$ lista administrativos
$ lista comerciais
$
Existe um limite de nove argumentos que podem ser referenciados, de $1 a $9. No entanto, existe um comando designado "shift" que permite ao Shell ignorar o primeiro elemento e renumerar os restantes de tal modo que se tem acesso a um 10º argumento. Deste modo é possível escrever um procedimento shell que manipule mais de 9 argumentos.
Outro modo de aceder a todos os argumentos, mesmo que sejam mais de 9, é pela notação $*. Esta expande para todos os argumentos que foram dados na invocação do procedimento shell. $* é o equivalente de $1 $2 $3 $4 ........ para todos os argumentos.
O pârametro $# permite obter o número total de argumentos específicos, quando o procedimento shell foi invocado. Por exemplo, se considerarmos um procedimento "contar":
$ cat contar
echo $# elementos
$ contar uvas macas laranjas peras
4 elementos
$ contar luis joao antonio
3 elementos
$
este procedimento simplesmente indica o número de elementos (argumentos) fornecidos na linha de comando. Esta facilidade é útil quando se pretende verificar se o procedimento shell foi chamado com o número correcto de argumentos.
O nome do procedimento shell é, ele mesmo, considerado o argumento zero ($0). O nome não é contabilizado em $#, como se verifica pelos exemplos dados.
Muitos dos exemplos que foram fornecidos, incluem o comando echo, que escreve os seus argumentos no standard output. Este comando é bastante útil quando se escrevem procedimentos shell; serve para fornecer indicações do processamento realizado, mensagens de erro ou resultados. Serve igualmente para indicar pedidos ao utilizador num procedimento interactivo e pode mesmo constituir uma ferramenta de depuração dos procedimentos desenvolvidos ou em desenvolvimento.
Na prática os procedimentos shell são melhor compreendidos e mais fáceis de ler quando colocados os seus argumentos entre aspas, tornando a mensagens um bloco único para o comando echo; um só argumento.
A protecção da mensagem pode ser efectuada pelo uso de plicas (') ou aspas ("). Se utilizarmos aspas é possível obter o valor das variáveis:
$ echo "Como estas $LOGNAME"
Como estas luis
$
LOGNAME é uma das variáveis Shell especiais. A Shell atribui a logname o nome do utilizador que iniciou a sessão no sistema.
Se se usar plicas os valores das variáveis Shell não são substituidos:
$ echo 'Como estas $LOGNAME'
Como estas $LOGNAME
$
mas podem existir situações onde se pretenda esta protecção:
$echo 'Valor total em dolares: $1023' | mail joao
$
Se for necessário utilizar o simbolo dolar ($) mas também e em simultâneo o uso de variáveis, recorre-se ao uso do simbolo \ para proteger o caracter especial:
$ quantia=1023
$ echo "Valor total em dolares \$$quantia" | mail joao
$
Quando se utiliza o comando echo existem algumas sequências de caracteres especiais que podem ser usadas de forma a modificar o output. Estas sequências especiais de caracteres são precedidas pelo simbolo (\) seguido por uma letra, por exemplo, \n.
Normalmente o comando echo inclui após o seu output o caracter de nova linha (line feed). A sequência \c pode ser usada para desligar o line feed ou mudança de linha:
$ echo "Como estas $LOGNAME \c"
Como estas luis $
Neste caso a prompt de sistema aparece na mesma linha que a mensagem. A sequência \c torna-se útil quando se escrevem procedimentos shell interactivos; pedidos de valores e opções de menu.
A sequência \n é usada para colocar linhas adicionais no output e a sequência \t coloca tabs (tabulação) no output. Se pretendermos enviar os parabéns a um utilizador:
$ echo "Feliz aniversario Paula! luis" | mail paula
$
A aparência da mensagem pode ser melhorada usando as sequências referidas:
$ echo "\tFeliz aniversario Paula \n\t\t\tluis" | mail
paula
$
Na escrita de procedimentos shell estas sequências podem poupar trabalho e tempo de execução, uma vez que um só comando echo pode substituir vários. Suponha que se pretende, no âmbito de um procedimento shell, produzir um cabeçalho para um relatório. Podemos utilizar vários comandos echo da seguinte forma:
agora=`date`
echo "" > relatorio
echo "" >> relatorio
echo "Proj SEDE: Dados $agora" >> relatorio
echo "" >> relatorio
echo "" >> relatorio
ou podemos utilizar apenas uma linha de comando:
now=`date`
echo "\f\n\nProjecto SEDE: Dados\t\t\t$agora\n\n" > relatorio
Neste último exemplo utilizou-se também a sequência \f, que coloca uma quebra de página (form feed) no output. Esta sequência assegura que o relatório começa no topo da página quando é impresso.
É possível, dentro de cada procedimento Shell, o uso de vários comandos destinados a realizar as tarefas necessárias para alcancar dos objectivos do utilizador.
Para controlo do fluxo de programação são utilizadas estruturas típicas como é o caso de if...else e while...do. Estas estruturas designam-se por estruturas de controlo.
O objectivo deste texto de programação em Shell é introduzir as estruturas mais comuns e pretende, de forma ligeira, dar uma visão geral das possibilidades da linguagem Shell e do seu uso.
Quando se cria um novo utilitário ou programa é uso corrente entre os programadores a criação de um protótipo em Shell script (procedimento shell) para testar a validade das soluções encontradas.
A grande vantagem dos procedimentos shell é a facilidade de os modificar; não é necessária recompilação, ligação (linkagem) do código e proceder à sua montagem de cada vez que se procede a uma alteração.
No uso dos Shell script é também fácil verificar e melhorar o seu correcto funcionamento (depuração - debug) uma vez que existem opções para utilizar o comando sh com facilidade de traçagem.
Quando se assegura que o programa executa o pretendido e se estabeleceu o aspecto de êcran, pedidos de valores e listagem (interface com o utilizador), pode-se então codificar numa linguagem de programação (por exemplo C) para maior eficiência; os programas compilados são mais rápidos (tempo de execução) que os procedimentos Shell para não-programadores a escrita de procedimentos Shell constitui uma boa introdução para os princípios básicos de programação.
Para ilustrar o uso de comandos de fluxo de controlo vamos utilizar o procedimento shell simples "lista" já atrás referido, melhorando-o e expandindo-o embora a linha básica do comando se mantenha a mesma.
sort +1 -2 pessoas | tr -d "[0-9]" | pr -h distribuicao | lp
Esta linha constitui o coração do procedimento. O comando será melhorado e adaptado a diferentes necessidades que serão apresentadas; quando o exemplo não for sufuciente para ilustrar as novas facilidades serão igualmente introduzidos outros.
A primeira tentativa de realização do procedimento lista teve o seguinte aspecto:
$ cat lista
sort +1 -2 pessoas | tr -d "[0-9]" | pr -h distribuicao | lp
$
Como foi já referido, este procedimento trata apenas o conteúdo do ficheiro pessoas.
Suponhamos que temos três ficheiros: alunos10, alunos11 e alunos12 e pretendemos correr o comando lista para cada um destes ficheiros.
Uma possibilidade é possuir três diferentes procedimentos para tratar os três diferentes ficheiros; o aspecto deles seria semelhante sendo alterado o nome do ficheiro pessoas pelos nomes de cada um dos ficheiros sucessivamente.
Uma solução melhor é adaptar o procedimento lista de forma a lidar com os três ficheiros. Podemos faze-lo, recorrendo ao comando for:
A forma geral do comando for é :
for < variavel > in < lista de valores >
do < bloco de comandos a repetir até aparecer "done"
>
done
O comando for, define a variável a tomar para os vários ciclos. Para cada um dos valores tomados, executando a sequência de comandos entre as palavras chave do...done. Quando já não existem mais valores diferentes para a variável tomar, os comandos a seguir à palavra chave done são executados.
O procedimento lista fica com o seguinte aspecto, implementando o comando for:
for fich in alunos10 alunos11 alunos12
do
sort +1 -2 pessoas | tr -d "[0-9]" | pr -h distribuicao | lp
done
A primeira linha define a variável shell fich, que toma os valores alunos10, alunos11 e alunos12, sucessivamente. A variável fich é utilizada pelo comando sort. O valor corrente da variável indica o ficheiro do mesmo nome a ser processado pela linha de comando que começa por sort e acaba com lp.
O output desta versão do procedimento lista são três listagens para a impressora, uma por cada ficheiro mencionado a seguir à palavra chave in.
Podemos usar metacaracteres nos procedimentos Shell. O exemplo do uso do asterisco (*) no procedimento lista, facilita a escrita de código:
for fich in alunos*
do
sort +1 -2 pessoas | tr -d "[0-9]" | pr -h distribuicao | lp
done
A utilização de alunos* é expandida para uma lista de todos os ficheiros que no directório corrente começem por alunos e tenham qualquer outra terminação.
Podemos omitir a palavra chave in; a lista de valores utilizada, por defeito, passa aos argumentos fornecidos na linha de comando que invocou a Shell.
Por exemplo, o procedimento lista:
for fich
do
sort +1 -2 pessoas | tr -d "[0-9]" | pr -h distribuicao | lp
done
Gera três listas se for chamado pelo comando:
$ lista alunos10 alunos11 alunos12
Mas gera apenas uma lista se for chamado por:
$ lista pessoas
O procedimento torna-se de uso mais geral e por isso mais útil, uma vez que não definimos à priori o número e valores que a variável de ciclo pode tomar.
Vamos rever o procedimento Shell lista original:
sort +1 -2 pessoas | tr -d "[0-9]" | pr -h distribuicao | lp
Já se concluiu que se pode tornar o procedimento geral a qualquer ficheiro colocando a variavel $1, que corresponde ao argumento em lugar do nome do ficheiro:
sort +1 -2 $1 | tr -d "[0-9]" | pr -h distribuicao | lp
Agora podemos gerar a lista qualquer que seja o ficheiro quando invocarmos o procedimento lista.
No entanto, se não indicarmos nenhum argumento:
$ lista
Nada acontece... A causa de nada acontecer deve-se ao facto de a Shell tentar substituir o valor de $1 e como não existe nada a substituir, o comando a executar fica:
sort +1 -2 | tr -d "[0-9]" | pr -h distribuicao | lp
Quando o comando sort não encontra nenhum nome de ficheiro assume que deve ordenar o standard input.
O resultado final é que o procedimento lista espera que o utilizador forneça os nomes que se pretendam colocar na lista de distribuição. Esta facilidade pode ser útil, mas então devemos indicar ao utilizador que se espera a entrada da lista de nomes.
Vamos assumir, no entanto, que se pretende que o procedimento lista trabalhe apenas com ficheiros previamente tratados. De modo a evitar a situação atrás descrita, é necessário inserir no procedimento a verificação de existência de argumento quando da invocação do comando; operação designada por validação:
if test $# -eq 0
then echo "Deve fornecer nome do ficheiro"
exit 1
fi
sort +1 -2 $1 | tr -d "[0-9]" | pr -h distribuicao | lp
A primeira linha do exemplo testa se o número de argumentos do procedimento lista é zero, isto é, nulo. Introduziram-se três novos elementos no exemplo: o comando if, o comando test e a palavra chave exit.
O comando if: as palavras chave relacionadas com este comando são if, then e fi. A estrutura geral é a seguinte:
if < se o comando tem sucesso >
then < executar o bloco até encontar "fi" >
fi
Para tornar o programa mais fácil de ler é usual indentar os comandos entre then e fi como demonstrado no exemplo.
Quando um comando tem sucesso, diz-se que retorna um valor verdadeiro. O valor de verdadeiro é, em UNIX, zero. Se o comando falha é retornado um valor diferente de zero.
No exemplo dado, usou-se o comando test para verificar se o número de argumentos é zero. Se for verdade, obviamente que nenhum nome de ficheiro foi fornecido quando se invocou o comando; test retorna uma valor diferente de zero.
Cada uma das palavras chave deve ser a primeira da linha de forma a ser reconhecida pelo Shell, se se coloca noutro qualquer local pode trazer problemas. Por exemplo se se tentar executar o ficheiro:
if test $# -eq 0 then
echo "Deve fornecer nome de ficheiro"
exit 1
fi
sort +1 -2 $1 | tr -d "[0-9]" | pr -h distribuicao | lp
que possui a palavra chave then no fim da linha. O resultado obtido é o seguinte:
$ lista pessoas
lista: syntax error at line 4: 'fi' unexpected
$
O comando test é provavelmente um dos mais úteis para usar em conjunto com o comando if. No entanto qualquer comando pode ser usado em conjunção com o comando if. Por exemplo:
if cd /aa/sigrup2/luis/docs
then echo ficheirinho
cat ficheirinho
fi
Se o comando cd for bem sucedido, então o ficheiro ficheirinho é visualizado. No entanto, uma tentativa para mudar o directório falhar por qualquer razão, nada acontece.
No exemplo apresentado, se não for dado um nome de ficheiro é aconselhável a impressão de uma mensagem de erro e terminar o procedimento sem executar o comando sort. Normalmente o procedimento shell termina quando o fim do ficheiro é atingido. Se se pretender acabar terminar o procedimento em função de qualquer acontecimento, então deve-se usar o comando exit.
O comando que usamos no procedimento anteriormente descrito foi exit 1. A colocação de argumento no comando serve para indicar que o valor retornado pelo procedimento é diferente de zero pelo que ocorreu um erro devido à falta de indicação de um ficheiro como argumento.
Na construção correcta de um procedimento devemos colocar um comando exit no fim do ficheiro:
if test $# -eq 0
then echo "Deve fornecer nome de ficheiro" > &2
exit 1
fi
sort +1 -2 $1 | tr -d "[0-9]" | pr -h distribuicao | lp
exit 0
Esta modificação assegura que o procedimento retorna um valor zero quando executado correctamente. Assim pode-se usar o procedimento lista inserido num comando if de outro procedimento Shell:
if lista pessoas
then echo Listagem realizada
fi
No procedimento lista revisto, não referimos uma pequena alteração. O comando echo foi modificado de modo a imprimir a mensagem de erro no output de diagnóstico, onde este deve ser colocado, em vez do standard output. No nosso exemplo não tem mal a mensagem ser colocada no standard output porque o procedimento em causa escreve o seu output na impressora; a única coisa que aparece no terminal é a mensagem de erro. No entanto, se se modificar o procedimento lista para escrever para o standard output e encadearmos (usando o pipe |) o comando com o comando lp para imprimir a lista criada, a mensagem de erro é também impressa!
A escrita de mensagens de erro para o output de diagnóstico evita esta situação desagradável. Num procedimento Shell que eventualmente pode ser usado encadeado com qualquer outro ou redireccionado para um ficheiro, é importante que as suas mensagens de erro sejam escritas no output de diagnóstico.
O valor dado ao comando exit é opcional; pode-se simplesmente escrever exit. Neste caso o valor retornado pelo procedimento é o mesmo que o valor retornado pelo último comando que foi executado, antes do procedimento ter terminado.
No caso do exemplo lista não é muito normal ser usado por um outro procedimento shell, pelo que o valor de retorno do comando exit não é importante. Nos próximos exemplos não será tomado em conta a atribuição de valores de retorno.
A palavra chave else faz parte do comando if. A sua actuação enquadra- se no seguinte esquema geral:
if < se o comando tem sucesso >
then < executar o bloco até encontar "else"" >
else < executar o bloco até encontrar "fi" >
fi
Podemos assim reescrever o procedimento lista:
if test $# -eq 0
then echo "Deve fornecer nome de ficheiro" > &2
else sort +1 -2 $1 | tr -d "[0-9]" | pr -h distribuicao | lp
fi
Desta vez não é necessário utilizar o comando exit porque o comando sort, a seguir ao else, apenas é executado se o número de argumentos for maior que zero. Assim como o comando if, as palavras chave then, fi e else tem de aparecer no início da linha.
Trata-se de uma combinação da palavra chave else e comando if. Para exemplificar analisemos o que acontece quando o procedimento lista é invocado com um ficheiro que não existe:
$ lista concorrencia
sort: can't open: concorrencia
pr: -- empty file
$
Se um utilizador inexperiente utiliza o comando lista e desconhece o significado de sort e pr, a mensagem que obtem deixa-o confuso. Será melhor verificar a existência do ficheiro antes de invocar o utilitário sort.
Para realizar a operação descrita, é necessário outro comando if para testar a presença de um ficheiro:
if test $# -eq 0
then echo "Deve fornecer nome de ficheiro" > &2
elif test ! -s $1
then echo "ficheiro inexistente $1" > &2
else sort +1-2 $9 | tr -d "[0-9]" | pr -h distribuicao | lp
fi
O segundo comando test verifica se existe um ficheiro com o nome fornecido. Assim o comando sort apenas é executado se for dado um nome de ficheiro. O mesmo resultado pode ser obtido usando um segundo comando if a seguir à palavra chave else:
if test $# -eq o
then echo "Deve fornecer nome de ficheiro" > &2
else if test ! -s $1
then echo "ficheiro inexistente $1" > &2
else sort +1-2 $9 | tr -d "[0-9]" | pr -h distribuicao | lp
fi
fi
Desta vez o programa possui dois comandos if separados; um indentado no outro. Esta segunda forma é diferente do uso de elif, que faz parte integrante do comando if, pelo que se possui um só comando if.
Existem casos onde o uso da palavra chave elif não proporciona os resultados esperados, pelo que é necessário utilizar um conjunto de comandos if indentados.
No exemplo fornecido, o segundo if não está no inÍcio da linha, o que parece quebrar as regras de sintaxe; mas a regra indica que as palavras chave tem de ser as primeiras no comando.
Normalmente significa que devem ser a primeira na linha, o que parece quebrar as regras, mas se o comando seguir uma palavra chave, obtêm-se duas palavras chave, uma a seguir à outra e não há problemas.
O comando test não faz parte do Shell mas destina-se a ser usado dentro dos procedimentos Shell. Alguns exemplos deste comando foram já fornecidos; basicamente os argumentos do comando test formam uma expressão. Se a expressão for verdadeira o comando test retorna o valor zero (teste bem sucedido). Se o test falhar, o comando retorna um valor diferente de zero.
Existem três tipos distintos de testes que podem ser executados pelo comando test:
Para cada tipo de teste existe um conjunto de primitivas que constroem a expressão avaliada pelo comando test. Estas primitivas descrevem as propriedades a serem testadas.
Existem também operadores que podem ser usados para inverter o significado de cada expressão e para combinar expressões.
Estes testes relacionam dois valores - numeros - que podem ser representados por variáveis shell. A forma geral da expressão de teste é :
N < primitiva > M
As primitivas que podem ser usadas na expressão de testes são:
-eq os valores de M e N são iguais
-ne os valores de N e M são diferentes
-gt N é maior que M
-lt N é menor que M
-ge N é maior ou igual a M
-le N é menor ou igual a M
Eis alguns exemplos do uso destes primitivas:
utilizadores='who | wc -l'
if test $utilizadores -gt 8
then echo "mais de 8 pessoas no sistema"
fi
A primeira linha do ficheiro atribui à variável shell utilizadores o valor resultante do encadeamento de comandos who | wc -l (pipe); contagem do número de utilizadores que se encontram a utilizar o sistema. O valor obtido é comparado com o valor 8 e se for maior é impressa uma mensagem apropriada.
O exemplo seguinte assume que o procedimento necessita de um argumento, que deve ser um directório:
este='ls | wc -l'
aquele='ls $1 | wc -l'
if test $este -ne $aquele
then echo "Directório corrente e $1 não coincidem"
fi
Novamente usamos o encadeamento de comandos envolvendo o comando wc; desta vez para contar o número de ficheiros no directório corrente e também contar o número de ficheiros no directório dado. Estes são comparados os dois valores obtidos e impressa a mensagem apropriada.
O último exemplo,
if test $# -eq 0
then echo "Deve fornecer nome de ficheiro" > &2
else sort +1-2 $9 | tr -d "[0-9]" | pr -h distribuicao | lp
fi
é o único que foi já referido. $# corresponde ao número total de argumentos dados do procedimento shell invocado. É efectuado o teste para verificar se o número é zero e se tal for é dada uma mensagem de erro.
Na execução dos testes são tomados valores numéricos, pelo que se definirmos três variáveis shell:
number = 1
nombre = ' 1'
numero = 00001
Todos são considerados equivalentes utilizando a primitiva -eq. Todos os zeros ou espaços remanescentes usados na definição dos valores são ignorados.
A Shell apenas trata números inteiros; se se tentar usar:
num1 = 1.0
num2 = 1.3
São considerados iguais e possuem o mesmo valor que as três variáveis anteriormente mencionadas.
Os números negativos (inteiros) estão disponíveis em Shell. Suponhamos a existência do seguinte procedimento:
$ cat sinal
if test $1 -ge 0
then echo "argumento positivo"
else echo "argumento negativo"
fi
$ sinal 2300
argumento positivo
$ sinal -871
argumento negativo
$
Os valores negativos são frequentemente obtidos depois de efectuados cálculos aritméticos em variáveis shell usando o comando expr, a descrever ainda neste texto.
Estes testes estão relacionados com a existência, características e propriedades dos ficheiros. A forma geral da expressão a testar para uso do comando test com ficheiros é :
< primitiva > nome do ficheiro
As primitivas mais comuns neste tipo de testes são:
-s verificar se o ficheiro existe e não está vazio
-f verificar se se trata de um ficheiro ordinário, não directório
-d verificar se o ficheiro é um directório
-w verificar se o ficheiro permite escrita
-r verificar se o ficheiro permite leitura
Num exemplo anterior foram comparados o número de ficheiros do directório corrente contra o número de ficheiros do directório especificado. Suponhamos que o nome dado em argumento não é de um directório. O procedimento iria provocar, neste caso, uma resposta incorrecta, uma vez que o output de wc seria uma linha, com uma mensagem de erro, uma vez que apenas se procede à contagem de linhas e não à leitura do seu conteúdo.
Assim devemos verificar se o nome especificado corresponde ao de um directório ou não:
este='ls | wc -l'
if test -d $1
then aquele='ls $1 |wc -l'
else echo "$1: nao e directorio"
fi
if test $este -ne $aquele
then echo "directorio corrente e $1 nao coincidem"
fi
Verificar se o ficheiro é um directório implica que exista! Se nada existir com o nome especificado, logo não pode ser um directório. Embora tenhamos já o teste apropriado realiza-se a atribuição dos valores às variáveis shell.
Em consequência, é necessário reorganizar o procedimento shell:
if test -d $1
then aquele='ls $1 |wc -l'
este='ls | wc -l'
if test $este -ne $aquele
then echo "directorio corrente e $1 nao coincidem"
fi
else echo "$1: nao e directorio"
fi
Este procedimento constitui um exemplo de um comando if indentado noutro. Repare-se que cada comando if tem associado o seu fi.
Na prática, é mais fácil lidar com as condições de erro ou excepção primeiro e depois, prosseguir com os detalhes do que se pretender fazer, caso tudo esteja bem. Neste caso significa testar se o argumento dado é um directório ou não. Para implementar o referido utiliza-se o ponto de exclamação (!) que é o operador de negação:
if test ! -d $1
then echo "$1: nao e directorio"
else aquele='ls $1 |wc -l'
este='ls | wc -l'
if test $este -ne $aquele
then echo "directorio corrente e $1 nao coincidem"
fi
fi
O operador ! inverte o sentido da primitiva -d; o valor retornado pelo comando test é zero (verdadeiro) se o nome dado não for um directório. O operador ! e a primitiva -d constituem argumentos separados para o comando test, pelo que é necessário um espaço entre estes.
Talvez a facilidade mais usada para no comando test para ficheiros, seja a verificação da sua existência. A primitiva -s verifica se o ficheiro existe e ainda se possui alguma informação; verificação de ficheiro não vazio. A primitiva -s foi usada no procedimento lista:
if test $# -eq o
then echo "Deve fornecer nome de ficheiro" > &2
else if test ! -s $1
then echo "ficheiro inexistente $1" > &2
else sort +1-2 $9 | tr -d "[0-9]" | pr -h distribuicao | lp
fi
fi
A primitiva -s foi usada em conjunção com o operador !; o que significa, não (o ficheiro existe e não é ficheiro vazio), traduzindo: se o ficheiro não existir ou for vazio. Normalmente utiliza-se esta forma de especificação das expressões, não para complicar mas para tratar as condições de erro primeiro.
Estes testes são utilizados para cadeias de caracteres (strings). Podem ser subdivididos em testes que comparam cadeias de caracteres e testes de existência de uma cadeia de caracteres.
A estrutura de expressão para testes de comparação de cadeias de caracteres é:
S < primitiva > R
onde existem duas primitivas que podem ser usadas:
= verifica se as cadeias de caracteres são iguais
!= verifica se as cadeias de caracteres são diferentes
A primitiva != é um argumento unico ao comando test - não existem espaços entre os simbolos ! e =.
Porque estão a ser comparadas cadeias de caracteres, não valores numéricos, duas variáveis assim definidas:
number=1
numero=00001
não são comparadas como equivalentes. Se se possuir outra variável Shell definida por:
nombre=' 1'
nunca seria comparada como equivalente com '00001'. A forma como se compara com '1', depende da forma como o teste é realizado. Se se tiver:
test $number = $nombre
as cadeias de caracteres são comparadas como equivalentes, porque os espaços da variável nombre são "absorvidos" pelos espaços entre os argumentos do comando test. Se se pretender preservar os espaços nas cadeias de caracteres então é necessário colocar as variáveis entre aspas.
test "$number" = "$nombre"
neste caso as cadeias de caracteres não são iguais A seguir são dados alguns exemplos do seu uso:
if test "$1" = ""
then echo "Deve fornecer nome de ficheiro" > &2
else sort +1-2 $9 | tr -d "[0-9]" | pr -h distribuicao | lp
fi
Esta é uma forma diferente de testar a presença de um argumento. Verifica-se se o argumento comparando-o com a cadeia de caracteres vazia.
O próximo exemplo demonstra como se pode restringir um procedimento shell de tal forma que só um dado utilizador o pode usar, independentemente de outros utilizadores terem permissão de execução do ficheiro shell.
if test $LOGNAME != mariana
then echo Este comando e restricto - acesso negado
exit
else .........
fi
O comando test possui outras expressões para tratar a presença ou ausência de uma cadeia de caracteres. O formato da expressão é :
< primitiva > S
e as primitivas disponíveis são:
-z verificar se a cadeia de caracteres é vazia
-n verificar se a cadeia de caracteres não é vazia
A presença de uma cadeia de caracteres pode ser também verificada pelo comando simples:
test S
Agora temos novas forma de tester a presença de um argumento:
if test -z "$1"
then echo "Deve fornecer nome de ficheiro"
else .........
fi
verificar se o primeiro argumento é uma cadeia de caracteres vazia,
if test ! -n "$1"
then echo "Deve fornecer nome de ficheiro"
else .........
fi
verificar para NÃO (cadeia de caracteres não vazia), e
if test ! "$1"
then echo "Deve fornecer nome do ficheiro"
else .........
fi
verifica para NÃO (cadeia de caracteres presente).
Em geral quando se lida com cadeias de caracteres é aconselhável delimita-las recorrendo ao uso de aspas. É especialmente importante no caso de se utilizar uma variável shell que pode ser uma cadeia de caracteres vazia. Se se não colocar aspas, no caso descrito, surge uma mensagem de erro da Shell:
$ cat testarg
if test ! -n $1
then echo argumento inexistente
else echo argumento: $1
fi
$ testarg
testarg: test: argument expeted
O erro deve-se ao facto do comando test ler, após a substituição do primeiro argumento por $1:
test ! -n
o que é um comando incompleto.
Para a maior parte dos casos, o mais provável é recorrer a aspas em vez de apóstrofes. A razão desta escolha é devida ao facto de a substituição pelas variáveis shell não ocorrer entre apóstrofes. Assim se se tiver duas variáveis:
fruto = maca
bolo = maca
O comando
test "$fruto" = "$bolo"
compara as duas cadeias de caracteres "maca" e "maca", que são iguais. Enquanto
test '$fruto' = '$bolo'
compara as duas cadeias de caracteres "$fruto" e "$bolo", que são diferentes.
Existem dois operadores, -a e -o, para combinar várias expressões de teste num único comando test. O operador -a representa o operador lógico "and", onde o resultudo é verdadeiro apenas quando ambas as expressões comparadas são verdadeiras. O operador -o representa o operador lógico "or", onde para que o resultado seja verdadeiro basta que uma das expressões comparados o seja.
Por exemplo, suponhamos a existência de um procedimento shell denominado append, que é invocado da seguinte forma:
$ append fich1 fich2
$
e tem o efeito de adicionar o fich1 ao final do ficheiro fich2. Pode-se combinar as verificações necessárias para os ficheiros - permissões de leitura e escrita - num único comando if:
if test -w $2 -a -r $1
then cat $1 >> $2
else echo impossivel executar comando
fi
Do ponto de vista do utilizador, este processo não é tão bom como a realização dos testes separados; apenas se produz uma mensagem de erro para as duas diferentes condições.
Testando cada condição isoladamente, como é dado a seguir,
if test ! -w $2
then echo $2 sem permissao de escrita
else if test ! -r $1
then echo $1 sem permissao de leitura
else cat $1 >> $2
fi
fi
É possível fornecer ao utilizador mensagens de erro claras e concretas.
O procedimento shell lista, com todos os melhoramentos introduzidos (verificação de argumentos e existência de ficheiros), lida apenas com um ficheiro de cada vez que é invocado. Uma melhoria adicional é possibilitar a existência de mais do que um argumento, recorrendo à estrutura repetitiva.
A verificação da existência de um ficheiro pode ser colocada dentro de um ciclo:
for fich
do if test ! -s $fich
then echo "ficheiro $fich inexistente" > &2
else sort +1-2 $fich | tr -d "[0-9]" | pr -h distribuicao | lp
fi
done
Este exemplo ilustra outra excepção à regra do comando if ter de ficar no início da linha; o if é reconhecido a seguir à palavra chave "do".
Agora que o procedimento consegue lidar com mais de um ficheiro, é importante o uso da palavra chave "else" em vez do comando exit, quando não existir um ficheiro com o nome dado.
Considere-se o procedimento shell com o seguinte aspecto:
for fich
do if test ! -s $fich
then echo "ficheiro $fich inexistente" > &2
exit
fi
sort +1-2 $fich | tr -d "[0-9]" | pr -h distribuicao | lp
done
Se forem dados dez nomes e o terceiro for errado, os restantes sete são ignorados. Usando a palavra chave "else" e não o comando exit, o comando executa todos os nomes que correspondam a ficheiros.
Se se invocar este procedimento sem qualquer argumento, o procedimento não faz nada, apenas devolvendo o controlo ao sistema. Se se redirecciona-se o output do comando para o standard output, seria obvio que alguma coisa estaria mal. Mas, dentro do procedimento shell, o output foi encaminhado para a impressora (através do pipe) pelo que não existe qualquer indicação de possíveis anomalias. Assim é necessário verificar a existência de argumentos:
if test $# -eq 0
then echo "Sintaxe: $0 ficheiro ....." > &2
exit
fi
for fich
do if test ! -s $fich
then echo "ficheiro $fich inexistente" > &2
exit
fi
sort +1-2 $fich | tr -d "[0-9]" | pr -h distribuicao | lp
done
Este teste ocorre antes do ciclo for, e se não forem dados nenhuns argumentos sai-se do procedimento imediatamente.
Repare que se modificou a mensagem de erro em relação ao procedimento que lidava com um argumento de cada vez. A nova mensagem forneçe a sinopse para uso do comando (forma geral). Repare-se igualmente no pormenor do uso de $0 para o nome de comando; se se decidir mudar o nome ao procedimento não é necessário mudar o texto da mensagem.
Até ao momento usou-se o comando for no procedimento lista para trabalhar com mais de um ficheiro. Existe um outro comando para o mesmo efeito que se referencia por while.
O comando while proporciona um outro metodo de repetição, executando vários comandos. As diferenças entre while e for baseam-se na forma de teste dos ciclos e dados necessários para o seu funcionamento.
O ciclo for requer uma lista de dados para os quais executa um conjunto de acções. O ciclo while executa um conjunto de acções enquanto se verifica uma condição especificada:
while < se o comando tem sucesso >
do < executar o bloco até encontar "done" >
done
Como é o caso do comando if, o comando mais habitual para utilizar com o while é o comando test, mas pode ser outro qualquer.
Um exemplo de outro comando usado em conjunção com o comando while é o comando shift. Este comando shift elimina o primeiro argumento $1, e renumera os argumentos seguintes. O argumento $2 passa a estar em $1, $3 em $2 e assim sucessivamente. O número total de argumentos, $#, é reduzido de uma unidade.
O procedimento shell pode ser reescrito usando estes dois novos comandos:
if test $# -eq 0
then echo "Sintaxe: $0 ficheiro ....." > &2
exit
fi
while test $# -gt 0
do if test ! -s $1
then echo "ficheiro $1 inexistente" > &2
else sort +1-2 $1 | tr -d "[0-9]" | pr -h distribuicao | lp
fi
shift
done
Enquanto existirem argumentos, como é verificado pelo teste $# maior que zero, os comandos entre "do" e "done" são executados. Um destes comandos, shift, que renumera os argumentos e decrementa $#. Quando $# é igual a zero, o ciclo termina e os comandos (se existirem) a seguir ao ciclo são executados; no caso do presente procedimento este termina a sua acção, por não possuir mais elementos a seguir é palavra chave "done".
Os comandos break e continue são usados para sair incondicionalmente (forçando o terminar do ciclo) nos comandos while e for. O comando continue não "quebra" o ciclo; este causa apenas que os comandos do resto do ciclo sejam ignorados na actual iteração, iniciando o ciclo completo na iteração seguinte.
Como exemplo de uso do comando continue utiliza-se o procedimento shell já acima referido:
for fich
do if test ! -s $fich
then echo "ficheiro $fich inexistente" > &2
exit
fi
sort +1-2 $fich | tr -d "[0-9]" | pr -h distribuicao | lp
done
Foi referenciado que se o comando fosse invocado com dez argumentos e o terceiro fosse errado, os restante sete eram ignorados. Pode-se contornar o problema usando a palavra chave "else" e deixando de o usar o comando exit. Em opção pode-se usar o comando continue como se demonstra no próximo exemplo.
Se não existir um ficheiro para um dado nome, ignora-se o resto do ciclo para essa iteração, para continuar com a próxima iteração.
for fich
do if test ! -s $fich
then echo "ficheiro $fich inexistente" > &2
continue
fi
sort +1-2 $fich | tr -d "[0-9]" | pr -h distribuicao | lp
done
o comando continue pode também ser usado no ciclo while:
if test $# -eq 0
then echo "Sintaxe: $0 ficheiro ....." > &2
exit
fi
while test $# -gt 0
do if test ! -s $1
then echo "ficheiro $1 inexistente" > &2
shift
continue
fi
sort +1-2 $1 | tr -d "[0-9]" | pr -h distribuicao | lp
shift
done
Desta vez, o uso do comando shift ocorre antes de continuar de modo a tratar o próximo ficheiro.
O comando break "quebra" o ciclo não apenas na iteração mas no todo. Em todos os exemplos fornecidos apenas existia um ciclo, pelo que o comando break levar à saída do procedimento do mesmo modo que o comando exit o faz.
Mas, numa situação onde se tem um ciclo dentro de outro (ciclos indentados), o comando break pode ser útil:
while teste1
do
< alguns comandos >
while teste2
do
< alguns comandos >
break
< mais comandos >
done
< mais comandos >
done
O comando break "quebra" o ciclo while teste2 e continua a iteração corrente do ciclo while teste1.
O comando until é muito parecido com o comando while, mas inverte o teste de término do ciclo. Enquanto, no caso do while, o ciclo prossegue até o teste retornar um valor falso, isto é , o ciclo continua até a condição de saída ser verdadeira, no caso do until, o ciclo termina assim que este receba um valor verdadeiro.
É possível inverter o ciclo no procedimento lista:
if test $# -eq 0
then echo "Sintaxe: $0 ficheiro ....." > &2
exit
fi
until test $# -gt 0
do if test ! -s $1
then echo "ficheiro $1 inexistente" > &2
else sort +1-2 $1 | tr -d "[0-9]" | pr -h distribuicao | lp
fi
shift
done
Através do uso do comando until em vez do comando while mudou-se a condição de teste de "enquanto existirem elementos" para "não existirem mais elementos".
Dois comandos simples que se podem tornar muito úteis são o true e false. Como os seus nomes deixam revelar, true retorna um valor verdadeiro (zero) e false retorna sempre um valor false (diferente de zero).
Estes comandos tem aplicação nos designados ciclos infinitos. Por exemplo, o procedimento:
while true
do
sleep 300
lpstat
done
será executado, visualizando o estado da impressora cada cinco minutos, para sempre, ou então até que seja interrompido por um utilizador que prima a tecla BREAK, ou o sistema parar!
Também se pode usar o comando until:
until false
do
sleep 300
lpstat
done
O comando sleep que foi usado nos exemplos anteriores, proporciona um modo de marcar o tempo; simplesmente não faz nada por um período de tempo especificado, que é dado em segundos.
Pretende-se incluir, no comando lista, algumas opções: a opção -j (juntos), de forma que, se for usada, todos os ficheiros especificados são ordenados e concatenados para produzir apenas uma única lista de distribuição. Se não se usar a opção -j cada ficheiro é impresso numa lista separada. A opção -j deve ser dada antes de qualquer nome de ficheiro, como é usual para comandos do sistema UNIX.
Obviamente que é agora necessário examinar o primeiro argumento do procedimento lista para verificar que é ou não -j. Podemos resolver o problema recorrendo ao comando if, mas um modo mais geral de procura de elementos em cadeias de caracteres é o comando case:
if test $# -eq 0
then echo "Sintaxe: [-t] $0 ficheiro ....." > &2
exit
fi
juntos=nao
case $1 in
-t) juntos=sim
shift ;;
-?) echo "$0: opcao $1 nao existe"
exit ;;
esac
if test $juntos = sim
then sort -u +1 -2 $* | tr -d "[0-9]" | pr -h distribuicao |
lp
else while test $# -gt 0
do if test ! -s $1
then echo "ficheiro $1 inexistente" > &2
else sort +1-2 $1 | tr -d "[0-9]" | pr -h distribuicao | lp
fi
shift
done
fi
O procedimento começa da mesma forma; com um teste para o caso de não serem dados argumentos. A seguir é inicializada a variável juntos que é uma variável auxiliar que indica o que fazer quando se executa o comando sort. Se a variável juntos tiver o valor "sim", todos os ficheiros serão ordenados e concatenados para produzir uma única lista, de outra forma serão tratados de forma a gerar listas separadas. Inicialmente o valor da variável juntos é colocada a "nao" - o seu valor por defeito.
A seguir temos o comando case. A forma geral deste comando é :
case < variavel > in
caso1) < se variavel é igual a caso1, executar todos os comandos
até ";;" - ignorar os restantes ";;" >
caso2) < se variavel é igual a caso1, executar todos os comandos
até ";;" - ignorar os restantes ";;" >
caso3) ... etc ...
esac
Básicamente existe uma lista de argumentos cuja existência tem de ser verificada de forma a despoletar a acção respectiva. O fim da cadeia de caracteres a comparar é delimitada pelo simbolo ")" e cada bloco de comandos que lhe correspondem é delimitado por dois simbolos seguidos ";" - ";;". O fim do comando case é indicado pela palavra chave "esac"; nesta estrutura é possível utilizar os metacaracteres ?, * e [-].
No exemplo anterior, pretende-se verificar o primeiro argumento do comando indicado no procedimento lista tem o valor "-t"; se sim atribui o valor "sim" é variável shell juntos.
Se o primeiro argumento for o simbolo "-" seguido de um outro qualquer caracter diferente de "t", será coincidente com o padrão "-?" no qual existe um bloco de comandos para dar uma mensagem de erro e a saída do procedimento.
A ordem em que são colocados os padrões para o comando case é importante. O primeiro padrão na lista verifica a cadeia de caracteres que implica acção. Se se tinha colocado o padrão "-?" antes de "-t" o resultado seria sempre a mensagem de erro uma vez que "-t" verifica "-?" - um simbolo "-" seguido de um caractere.
Depois de o procedimento testar a existência do argumento "-t" e atribuir um valor correspondente é variável juntos, examina-se o conteúdo da variável. Se o seu valor é sim, usa-se a notação $* para passar os argumentos restantes para um único comando sort. Adicionou-se a opção -u ao comando sort para assegurar que cada nome aparece apenas uma vez na lista. Se o valor da variável é não, então cada ficheiro dado em argumento é processado separadamente.
O procedimento pode parecer um processo demasiadamente complexo para resolver o problema pois era possível verificar a existência do argumento -t com o comando if em vez de recorrer a variáveis auxiliares. A razão de uso do comando case dá a possibilidade de criação de uma estrutura que facilita a adição de um novo padrão à lista dos já existentes.
Considere-se uma nova opção a adicionar ao procedimento: -m para colocar o resultado em várias colunas. Se a opção -m for usada os nomes aparecem em três colunas, caso contrário aparecem numa única coluna. É necessário utilizar uma opção adicional no comando de UNIX, pr, para produzir um output a várias colunas. Para o efeito é definida outra variável shell designada colunas que é inicializada à cadeia de caracteres vazia, por defeito, ou colocada ao valor "-3", se o procedimento lista for invocado com a opção "-m".
A passagem de uma só opção, quando existem várias, tem de ser acompanhada com novos cuidados, a não ser que se definam regras para a ordem de colocação das opções o que se torna pouco prático para o utilizador. Em consequência o comando case é envolvido por um comando while:
if test $# -eq 0
then echo "Sintaxe: [-t] [-m] $0 ficheiro ....." > &2
exit
fi
juntos=nao
colunas=""
while test $# -gt 0
case $1 in
-t) juntos=sim
shift ;;
-m) colunas ="-3"
shift ;;
-?) echo "$0: opcao $1 nao existe"
exit ;;
*) if test $juntos = sim
then sort -u +1 -2 $* | tr -d "[0-9]" | pr $colunas -h distribuicao
| lp
exit
else if test ! -s $1
then echo "ficheiro $1 inexistente" > &2
else sort +1 -2 $1 | tr -d "[0-9]" | pr $colunas -h distribuicao
| lp
fi
shift
fi ;;
esac
done
Existem quatro casos; os dois primeiros são as opções "-t" e "-m". O terceiro caso lida com as opções desconhecidas; o último caso trata dos casos restantes (indicado pelo padrão *), que supostamente processa os nomes dos ficheiros fornecidos.
Uma vez que o comando sort se encontra dentro do ciclo causado pelo comando while, é necessário adicionar um comando exit para evitar que o comando seja repetido várias vezes.
O procedimento shell lista está agora organizado de tal forma que é muito fácil adicionar novas opções, colocando-as na estrutura do comando case.
Por exemplo, é possível modificar o comando de forma a produzir o output para o standard output a não ser que seja dada a opção "-p". A forma de implementar esta opção é remover o comando lp do final da linha de encadeamento de comandos começada por sort e colocar o output num ficheiro temporário. Se a opção "-p" for dada, o ficheiro criado é redireccionado para a impressora, doutra forma, simplesmente se visualiza o ficheiro no standard output.
É possível usar um ficheiro temporário no directório corrente, mas não existe nada até à data que implique que o utilizador tenha permissões de escrita no directório corrente. Eventualmente, a falta de permissões de escrita pode ser um elemento de segurança! Em consequÊncia existe um directório especial designado /tmp destinado à criação de ficheiros temporários. O ficheiro /tmp dá permissões de escrita para todo o mundo. A seguir é apresentada a nova versão do procedimento lista que constituirá a versão final do procedimento:
Na versão final do procedimento lista utiliza-se mais uma variável shell, imprimir, como variável auxiliar para a opção de impressão e com o valor "nao" por defeito; adiciona-se outro caso; -p, para modificar o valor em caso de impressão para "sim".
A maior mudança ocorre na linha de comandos encadeados sort; retirou-se o comando final lp, deixando o comando pr como o último e direccionando o seu output para o ficheiro temporário "$0$$" residente no directório /tmp. Existe uma razão forte para a escolha do nome do ficheiro; uma vez que o directório /tmp é publico é necessário assegurar que o nome atribuído ao ficheiro é único, caso contrário outro qualquer utilizador pode eliminar o conteúdo deste ficheiro, colocando um seu ficheiro com o mesmo nome. A variável shell $$ fornece o número de processo em unix, correspondente ao comando corrente, que é um número único. Assim é possível ter dois utilizadores simultâneos do procedimento lista sem nenhum deles apagar o ficheiro dos outros, pois os respectivos nomes são diferentes. Claro que eventualmente o mesmo número de identificação do processo pode ocorrer para outro processo, mas nessa altura, a necessidade dos ficheiros temporários já terminou.
Para maior identidade usou-se também o nome do comando, $0, pelo que os ficheiros temporários criados em /tmp são do tipo lista2209. Não é necessário o uso do nome do comando nos ficheiros mas torna-se às vezes útil relacionar os ficheiros existentes em /tmp com os comandos que lhes deram origem. Por exemplo, quando se corrige um programa pode ser necessário examinar os ficheiros temporários que produziu; nem sempre se sabe o número de identificação do processo que lhes deu origem mas sabe-se o nome do comando que se está a corrigir.
#
# Este comando processa ficheiros contendo nomes e numeros
# de telefones.
# Os numeros são removidos e os nomes são impressos com um
# cabeçalho.
#
# As opções são:
#
# -t ordenar e juntar todos os ficheiros fornecidos
# -p redireccionar o ficheiro para a impressora
# -m imprimir nomes a tres colunas
#
if test $# -eq 0
then echo "Sintaxe: [-t] [-m] $0 ficheiro ....." > &2
exit
fi
juntos=nao
colunas=""
imprimir=nao
while test $# -gt 0
case $1 in
-t) juntos=sim
shift ;;
-m) colunas ="-3"
shift ;;
-p) imprimir=sim
shift ;;
-?) echo "$0: opcao $1 nao existe"
exit ;;
*) if test $juntos = sim
then sort -u +1 -2 $* | tr -d "[0-9]" | pr $colunas -h distribuicao
> /tmp/$0$$
if test $imprimir = nao
then cat /tmp/$0$$
else lp -c /tmp/$0$$
fi
rm /tmp/$0$$
exit
else if test ! -s $1
then echo "ficheiro $1 inexistente" > &2
else sort +1 -2 $1 | tr -d "[0-9]" | pr $colunas -h distribuicao
> /tmp/$0$$
if test $imprimir = nao
then cat /tmp/$0$$
else lp -c /tmp/$0$$
fi
rm /tmp/$0$$
fi
shift
fi ;;
esac
done
Versão final do shell script LISTA
Depois de executar o comando sort a variável imprimir é examinada, de modo a possibilitar a visualização em ecran do ficheiro ou o seu direccionamento para a impressora.
A seguir, o ficheiro temporário é eliminado do directório /tmp; esta operação é importante porque se trata de uma área utilizada pela comunidade e em consequência tem de existir disciplina no seu uso. Se existirem muitos ficheiros temporários pode acontecer que se esgote o espaço disponível para /tmp e levar ao mau funcionamento dos procedimentos que utilizam ficheiros temporários.
A gestão de espaço disponível cabe ao gestor de sistema UNIX - system administrator - que deve zelar pelo correcto funcionamento do sistema incluindo a eliminação periódica de todos os ficheiros de /tmp.
No entanto podem ocorrer problemas se se remover o ficheiro antes de este ter sido impresso. Assim para eliminar o ficheiro de /tmp utiliza-se o comando lp com a opção "-c" que obriga o spooler de impressora a criar uma cópia própria para utilização que será eliminada quando o ficheiro tiver sido impresso.
No último exemplo foram adicionadas algumas linhas, no início do comando linha, para o descrever. Este tipo de comentários é muito útil para quem tem de ler o procedimento e descobrir o que ele faz.
O caracter # é usado para introduzir comentários; embora no exemplo os comentários tenham ocupado uma linha completa não é necessário que assim seja. Os comentários podem também ser colocados no final de uma linha de comandos, no entanto, um comentários nunca pode ser colocado no início ou meio de uma linha de comandos.
Esta regra deve-se ao facto de a Shell quando depara com o simbolo #, a seguir a um espaço, ignora todo o que se encontrar à frente até ao caracter de nova linha.
Suponhamos que o comando lista tenha sido invocado e, por qualquer razão, o utilizador interrompe a sua execução através do uso da tecla BREAK.
Um sinal de interrupção é enviado ao processo (isto é, ao comando lista) o que faz com que este pare, independentemente do que estiver a fazer. Assim se se tiverem criado ficheiros temporários, que não foram ainda removidos, são deixados abandonados no directório /tmp para sempre ou até ao administrador do sistema os remover.
É aconselhável impedir estas ocorrências (principalmente se o temperamento do administrador do sistema não for dos melhores); para tal recorre-se a mecanismos que obriguem o procedimento a remover todos os ficheiros temporários criados, mesmo quando interrompido.
Existe um comando útil nestes casos - trap - deve-se especificar o comando a executar quando um dado sinal é recebido. A forma geral do comando é :
trap `argumentos do comando` sinal ...
O comando e os seus argumentos devem formar um só argumento para o comando trap, que se encerra entre plicas (`). Se se pretender executar mais de um comando então recorre-se ao uso do simbolo (;) que é o separador de comandos normal.
O sinal é especificado por um número e podem ser dados mais de um destes sinais. O sinal de uso mais geral é representado pelo número 2, que é o obtido quando se interrompe um processo, ou o sinal número 1 que se obtem quando o utilizador sai do sistema (logout) enquanto se está no meio do processo.
O uso do comando trap é exemplificado recorrendo-se ao procedimento lista para, em caso de interrupção ou disconecção do sistema, se apagarem todos os ficheiros temporários criados. Se tal ocorrer todos os ficheiros temporários são removidos e executa-se o comando exit.
if test $# -eq 0
then echo "Sintaxe: [-t] [-m] $0 ficheiro ....." > &2
exit
fi
juntos=nao
colunas=""
imprimir=nao
while test $# -gt 0
case $1 in
-t) juntos=sim
shift ;;
-m) colunas ="-3"
shift ;;
-p) imprimir=sim
shift ;;
-?) echo "$0: opcao $1 nao existe"
exit ;;
*) trap `rm /tmp/$0$$; exit` 2 1
if test $juntos = sim
then sort -u +1 -2 $* | tr -d "[0-9]" | pr $colunas -h distribuicao
> /tmp/$0$$
if test $imprimir = nao
then cat /tmp/$0$$
else lp -c /tmp/$0$$
fi
rm /tmp/$0$$
exit
else if test ! -s $1
then echo "ficheiro $1 inexistente" > &2
else sort +1 -2 $1 | tr -d "[0-9]" | pr $colunas -h distribuicao
> /tmp/$0$$
if test $imprimir = nao
then cat /tmp/$0$$
else lp -c /tmp/$0$$
fi
rm /tmp/$0$$
fi
shift
fi ;;
esac
done
Como existe a possibilidade de não existir nenhum ficheiro temporário no momento em que se recebe o sinal, o comando trap deve estar preparado para lidar com esta situação:
trap `rm /tmp/$0$$ 2> /dev/null; exit` 2 1
Se o comando rm produzir uma mensagem de erro dizendo que o ficheiro que se tenta remover não existe, não existe qualquer interesse em visualizar a mensagem mesmo quando redireccionada para o output de diagnostico. Para nos livrarmos da mensagem de erro redireccionamos o próprio output de diagnostico para um ficheiro dispositivo designado /dev/null. Este ficheiro /dev/null faz parte do sistema unix e tudo que é escrito nele desaparece.
O comando expr avalia os seus argumentos como uma expressão e escreve o seu resultado no standard output. Existem vários modos de uso deste comando, mas um dos mais úteis é a realização de calculo aritmético com as variáveis shell.
Exemplo do uso do comando expr:
$ cat soma3
expr $1 + $2 + $3
$ chmod 755 soma3
$ soma3 13 49 2
64
$
O comando soma3 imprime a soma de três números dados em argumento. Se forem dados mais de três números, os restantes são ignorados. Se forem dados menos de três números, é visualizada uma mensagem de erro:
$ soma3 13 49 2 64 1
64
$ soma3 13 49
expr: syntax error
$
O procedimento shell descrito é pouco útil, pois é possível utilizar directamente o comando expr:
$ expr 13 + 49 + 2 + 64 + 1
129
$ expr 13 + 49
62
$
Os operadores aritméticos permitidos no comando expr são:
+ adição
- subtração
* multiplicação
/ divisão
% resto
Cada operador e cada um dos operandos, forma um argumento separado para o comando expr pelo que tem de existir espaços entre todos eles.
Tomando um exemplo mais complexo; cálculo do resultado médio de jogadores num torneio de tenis, a partir de um ficheiro designado tennis que contém todos os dados necessários:
$ cat resultmedio
numero=`wc -l < $1`
total=0
contar=$numero
while test $contar -gt 0
do resultado=`sed -n ${contar}p $1 | tr -dc '[0-9]'`
total=`expr $total + $resultado`
contar=`expr $contar - 1`
done
resinteiro=`expr $total / $numero`
resdecimal=`expr $total % $numero \* 100`
echo Resultado medio: $resinteiro.$resdecimal
$ resultmedio tennis
Resultado medio: 8.900
Este exemplo utiliza todos os operadores. O primeiro passo é contar o número de linhas no ficheiro e atribuir o valor obtido à variável shell número. Ao contar as linhas é necessário utilizar o standard input de modo a obter apenas um valor numérico.
Se se tivesse declarado apenas "wc -l $1", o valor atribuído a número teria sido a cadeia de caracteres "10 tennis", porque o comando wc repete o nome do ficheiro.
A seguir são definidas mais duas novas variáveis: total para guardar o total dos resultados, inicializada a zero, e contar que controla a paragem do ciclo while utilizado, inicializada ao total de linhas existentes no ficheiro dado em argumento.
A seguir aparece um ciclo em que, para cada linha do ficheiro, coloca a variável resultado igual ao output da linha de comandos encadeada:
sed -n ${contar}p $1 | tr -dc '[0-9]'
O output do comando sed (stream editor) é a linha do ficheiro cuja posição é dada pela variável contar. O comando tr toma esta linha e apaga todos os caracteres excepto os numéricos - digitos. O valor da variável resultado é então atribuido à variável total e a variável contar é decrementada. O ciclo é repetido até todas as linhas do ficheiro terem sido processadas.
O passo final do procedimento é a divisão do resultado total pelo número de linhas para a variável resinteiro. As variáveis shell podem apenas lidar com inteiros, pelo que o resultado é arredondado para o número inteiro mais próximo. De forma possuir algumas casas decimais o operador resto é utilizado e a seguir multiplica-se o resultado pelo número de casas decimais pretendidas; 1 utilizar 1, 2 utilizar 10, 3 utilizar 100.
Um cuidado a ter com o operador de multiplicação (*) é a sua protecção, porque o simbolo * tem um significado especial para a Shell, pelo que se usar sem proteção obtemos uma mensagem de erro:
$ expr 2 * 3
syntax error
$
Quando se utiliza * como argumento no comando expr deve-se proteger o simbolo, de modo a evitar que a Shell tente expandir este a todos os nomes dos ficheiros do corrente directório. Existem várias formas de protecção:
$ expr 2 \* 3
6
$ expr 2 "*" 3
6
$ expr 2 '*' 3
6
$
No procedimento resultmedio foi usado o primeiro dos metodos descritos.
Existem outras utilizações para o comando expr. Podem-se comparar dois valores numéricos; podem-se comparar cadeias de caracteres ou verificar se uma cadeia de caracteres é igual a uma expressão regular. Todas estas facilidades produzem output para o standard output, pelo que podem ser usadas para atribuição de variáveis auxiliares.
Se o comando expr é utilizado em conjunção com o comando if é provável que o output normal de expr não seja pretendido, pelo que podemos utilizar /dev/null para o anularmos. Por exemplo:
if expr "$1" : "-." > /dev/null
then echo O argumento e uma opcao
else echo O argumento nao e uma opcao
fi
O procedimento verifica se o primeiro argumento é um caracter precedido pelo simbolo "-". Se o for, é assumido que se trata de uma opção ao comando. Se não se tivesse redireccionado o output para /dev/null, na expressão do comando expr, então 0 ou 1 (qualquer que fosse o valor retornado pelo comando) e uma mensagem apareceria no output. Note-se que para tratamento de cadeias de caracteres, o comando expr utiliza as expressões regulares existentes nos comandos grep e ed.
No inicio deste texto foi apresentado um simples procedimento shell que designamos por lista, com a seguinte versão original:
sort +1 -2 pessoas | tr -d "[0-9]" | pr -h distribuicao | lp
e foi apontado que o procedimento apenas funciona para o ficheiro explicitamente referido.
Quando se tem mais de um ficheiro para construir listas, um modo de o fazer é possuir um procedimento shell para cada um dos ficheiros. Este processo duplica o número de ficheiros necessários porque para cada ficheiro de nomes é necessário um procedimento shell específico: lista1 para o ficheiro alunos10, lista2 para o ficheiro alunos11, lista3 para o ficheiro alunos12 e assim sucessivamente.
Uma solução alternativa é combinar os comandos e os dados num único ficheiro. Se combinarmos o ficheiro pessoas juntamente com os comandos necessários para imprimir a lista de distribuição, o ficheiro fica com o seguinte aspecto:
sort +1 -2 << ! | tr -d "[0-9]" | pr -h distribuicao
| lp
Dalila 372112
Cristina 380177
Ana 371212
Paula 374321
Joana 380606
Ricardo 386622
Paulo 384578
!
A notação << ! constitui a parte importante do exemplo. Os simbolos << significa: tomar todo o resto deste ficheiro, até à linha contendo o argumento dado a seguir a "<<". No caso apresentado o argumento que sucede a "<<" é o simbolo "!". Assim todas as linhas até "!" tornam-se o input para o comando sort.
A esta facilidade em que os dados estão juntos com os comandos designa-se por "here documents".
Existem várias situações onde o uso de here documents é vantajoso. Por exemplo, quando se pretende dar ao utilizador uma longa mensagem sem recorrer ao uso de múltiplos comandos echo:
if test ! -s $1
then cat << end
Seu incompetente !!!
Acabou de fornecer um nome de ficheiro incorrecto.
Verifique os nomes de ficheiros no seu directório.
A seguir verifique se esta no directório pretendido.
Quando souber o que esta a fazer, tente novamente!!
end
Neste caso todas as linhas do procedimento shell, até à linha que contém a palavra "end", formam o input para o comando cat e são visualizadas no standard output.
A palavra "end" deve estar no início da linha, mesmo que alinhe o texto que forma o here document. É normal alinhar o texto de um procedimento para maior compreensão mas infelizmente os caracteres tab utilizados para indentar são copiados para o output.
Pode-se impedir o processamento dos caracteres tab num here document, usando a notação:
cat <<- end
Neste caso a palavra "end" pode ser também indentada.
Um here document pode ser também usado para chamar um programa interactivo de dentro do próprio procedimento. Suponhamos o seguinte procedimento:
troff -mm $1 | lp
mail $LOGNAME << +
A formatacao de $1 esta completa.
Foi direccionada para a impressora.
+
Este comando pode ser colocado em modo background para formatar um ficheiro; quando tiver sido formatado o utilizador é notificado através de uma mensagem via mail. A substituição das variáveis shell também ocorre dentro de um here document, se não se pretender a sua substituição basta colocar o simbolo "\" entre << e o caractere seguinte.
Nesta secção são discutidas duas formas distintas de entrada de dados. A primeira, consiste na invocação de um programa interactivo, como um editor de texto, de dentro do próprio procedimento shell. Neste caso é necessário assegurar que o input do utilizador é passado para o programa chamado.
A outra situação verifica-se quando um procedimento shell é escrito de forma a interagir com o utilizador; pretende-se questionar o utilizador para introdução de dados e em seguida ler esses dados para processamento.
O standard input pode ser passado para um programa interactivo invocado pelo procedimento shell usando a notação < &0. Por exemplo, se se tiver um procedimento shell para chamar o editor ed com uma prompt personalizada, o ficheiro em questão terão seguinte aspecto:
$ cat meued
ed -p '*' $* < &0
A utilização de "$*" passa todos os argumentos na invocação do procedimentos meued para ed. Uma vez que o ed aceita apenas um único nome de ficheiro bastaria ter colocado $1. O uso de "<&0" assegura que a entrada de dados do utilizador em meued também é passada para ed.
Normalmente a colocação de "<&0" não é necessária, o standard input é automaticamente passado para o programa invocado. Mas, mesmo com o sistema V do UNIX existem diferentes versões que tem comportamentos estranhos se não se colocar "<&0". Por exemplo:
$ cat meued
ed -p '*' $1
$
obtêm-se a seguinte resposta quando se tenta usar:
$ meued qualquerfich
1439
* 1,$p
onde o input dado é totalmente ignorado. Se tal se verifica, então é necessário mudar o procedimento para incluir "<&0".
Um outro exemplo é um procedimento shell para visualizar um ficheiro êcran a êcran usando o comando pr. Embora o comando pr não seja interactivo, quando usado com a opção -p este espera que se pressione RETURN antes de continuar.
Um procedimento shell para utilizar esta facilidade tem o seguinte aspecto:
$ cat pag
pr -tp121 $* <&0
$
Lembre-se que estes comandos devem ser colocados num directório que esteja incluído no caminho de pesquisa de comandos definido pela variável shell PATH.
Por vezes é necessário escrever um procedimento shell que exige a entrada de dados pelo utilizador para agir em conformidade com estes. Esta facilidade pode ser obtida graças ao comando read, que toma uma linha do input e atribui o seu valor a uma variável.
Um exemplo simples para demonstração:
$ cat exemp
echo "Diga qualquer coisa: \c"
read coisa
echo "Repito o que disse: $coisa"
$
A variável coisa é definida pela sua presença no comando read, sendo o seu valor definido pelo input que o utilizador fornece.
Quando o procedimento é chamado, obtemos:
$ exemp
Diga qualquer coisa: ola como vais
Repito o que disse: ola como vais
$
Mais de uma variável pode ser definida num único comando read. Neste caso, é primeira variável é atribuido o valor da primeira palavra do input enquanto à segunda variável é atribuido o valor da segunda palavra do input e assim sucessivamente.
Uma palavra é uma qualquer cadeia de caracteres separada por espaços ou tabs. Por exemplo a existência do procedimento shell contratacao, que adiciona uma linha a uma lista de empregados:
echo "Indique departamento, funcao, primeiro nome e último
nome"
read dep func ult prim
echo "Primeiro nome: $prim\nUltimo nome: $ult"
echo "$ult, $prim\t$dep\t$func" >> empregados
echo "Empregado adicionado a lista"
Quando usamos o procedimento, a interacção terão seguinte aspecto:
$ contratacao
Indique departamento, funcao, primeiro nome e ultimo nome
tecnico programador marco fernandes
Primeiro nome: marco
Ultimo nome: fernandes
Empregado adicionado a lista
$
Se existem mais palavras na linha de input que variáveis definidas, então as palavras mais à direita são atribuídas à última variável. Este facto é ilustrado por mais uma sessão de utilização do exemplo:
$ contratacao
Indique departamento, funcao, primeiro nome e ultimo nome
comercial vendedor armando menezes da silva ferreira
Primeiro nome: armando
Ultimo nome: menezes da silva ferreira
Empregado adicionado a lista
$
Os exemplos dados são apenas demonstrativos das capacidades do comando read. Um exemplo mais útil ocorre quando se pretende colocar vários programas sob o SCCS - uma ferramenta de auxilio a projectos de programação em linguagem C que envolvam muitos programas e vários programadores.
Cada linha de comando admin é bastante longa e a unica variação que ocorre é o nome do ficheiro, que tem de ser escrito duas vezes.
Em consequência do exposto faz sentido desenhar um procedimento shell, designado por projetese, que seja usado para colocar código fonte (ou documentação) na biblioteca referente ao projecto tese dos ficheiros SCCS. O procedimento projetese tem o seguinte aspecto:
echo "De o nome do ficheiro, um por linha\n"
while true
do
echo "? \c"
read linha # obter outro nome de ficheiro
if test "$linha" = ""
then exit # acabar se a linha for vazia
fi
if test ! -s $linha # verificar existencia do ficheiro
then echo nao existe ficheiro $linha
else admin -fi -i$linha /usr/luis/tese/s.$linha
fi
done
Primeiro é indicado que cada nome de ficheiro deve ser dado numa linha separada. A seguir é dado o prompt ? para informar que se esperam dados. Qualquer que seja o input fornecido pelo utilizador, presumivelmente um nome de ficheiro, será atribuido à variável linha.
A seguir é verificado se a linha não está vazia, se estiver o procedimento termina a sua execução. De outra forma verifica-se se o ficheiro existe e se existir, usamos o comando admin para o colocar na biblioteca SCCS.
Assim este procedimento toma nomes de ficheiros, um por linha, e por cada ficheiro válido coloca-o na biblioteca. Quando é detectada uma linha em branco sai-se do procedimento.
Na prática não é boa ideia usar uma linha branca como critério de terminação do procedimento. É muito fácil carregar na tecla RETURN duas vezes seguidas por acidente e pode ser frustante ter de invocar novamente o comando sempre que isso acontece.
A nova versão do procedimento projetese ignora as linhas em branco; se se escrever uma simplesmente é obtida novamente a prompt. É usada a convenção do ponto (.) para terminar a entrada de dados.
echo "De o nome do ficheiro, um por linha\n"
while true
do
echo "? \c"
read linha # obter outro nome de ficheiro
if test "$linha" = "."
then exit # acabar se existir um ponto
fi
if test "$linha" != "" # ignorar linhas em branco
then if test ! -s $linha # verificar existencia do ficheiro
then echo nao existe ficheiro $linha
else admin -fi -i$linha /usr/luis/tese/s.$linha
fi
fi
done
O que acontece se o utilizador não seguir as regras e fornecer mais de um nome de ficheiro por linha?, é possível colocar mais um teste para o efeito e dar a mensagem necessária ao utilizador:
echo "De o nome do ficheiro, um por linha\n"
while true
do
echo "? \c"
read linha # obter outro nome de ficheiro
if test "$linha" = "."
then exit # acabar se existir um ponto
fi
if test "$linha" != "" # ignorar linhas em branco
then continue
fi
if echo $linha | grep " " > /dev/null
then echo "Coloque apenas UM nome de ficheiro por linha"
continue
else if test ! -s $linha # verificar existencia do ficheiro
then echo nao existe ficheiro $linha
else admin -fi -i$linha /usr/luis/tese/s.$linha
fi
fi
done
O teste para verificar se existem espaços utiliza a característica do comando grep retornar uum valor verdadeiro (zero) sempre que acha a cadeia de caracteres de argumento (neste caso um espaço) e retorna um valor falso (diferente de zero) se não existir a cadeia de caracteres de argumento.
No caso presente, a existência da cadeia de caracteres é um erro - denuncia a existência de espaços - pelo que se usa o comando continue para ignorar o comando admin e tornar a colocar a prompt para a entrada de dados.
Na realidade seria melhor que o procedimento aceite vários nomes de ficheiro numa só linha e os trate de forma correcta. Neste ponto é tentador definir várias variáveis no comando read.
Mas a questão é quantas devem ser definidas. Pode-se pensar em usar um ciclo for, para processar os nomes de ficheiro, mas tal torna-se desnecessário, pois existe uma forma mais simples de realizar o pretendido como demonstrado a seguir:
echo "De o nome do ficheiro, um por linha\n"
while true
do
echo "? \c"
read linha # obter outro nome de ficheiro
if test "$linha" = "."
then break # acabar se existir um ponto
fi
if test "$linha" = "" # ignorar linhas em branco
then continue
fi
for file in $linha
do
if test ! -s $linha # verificar existencia do ficheiro
then echo nao existe ficheiro $linha
else admin -fi -i$linha /usr/luis/tese/s.$linha
fi
done
done
Existem muitos melhoramentos que é possível fazer a este procedimento. Por exemplo, foi assumido que todos os ficheiros chamados se encontram no directório de trabalho, mas que fazer caso o utilizador forneça o nome completo do ficheiro ou o seu caminho relativo (à posição onde se encontra o procedimento).
É necessário o uso do caminho para o ficheiro a seguir é opção -i, mas quando se cria o ficheiro SCCS apenas é necessário o nome do ficheiro. Existem várias formas de separar o nome do ficheiro do seu caminho. Uma consiste na utilização do comando expr, outra recorre ao comando sed, mas provavelmente o modo mais fácil é o uso de um comando de UNIX designado basename.
Outro refinamento consiste na adição da visualização da mensagem contida no comando help para o comando admin, se este falhar por qualquer motivo. Para implementar esta facilidade é necessário saber se o comando admin produziu mensagens de erro no standard output ou output de diagnóstico. A seguir é necessário recuperar o output e extrair o código de erro de modo a fornece-lo como argumento para o comando help.
Uma função é , em efeito, similar a um procedimento shell, isto é , trata-se de um conjunto de comandos UNIX a serem executados, invocados por um único nome na linha de comando. Mas, enquanto um procedimento shell deve ser contido num ficheiro com o nome que o utilizador pretenda, a função precisa apenas de ser definida na Shell.
O uso de funções em vez de procedimentos não é adequado para longas listas de comandos UNIX, mas uma função pode, de forma fácil, ser usada em lugar de um procedimento simples.
No início deste texto foi discutida a criação de uma versão própria do comando ls, de modo a usar sempre as opções -x e -F. Este comando pode ser definido pela função:
ls ()
{
/bin/ls -x -F $*
}
A primeira linha mostra o nome da função seguido de parentesis, (). As linhas contidas entre chaves "{ }" constituem o corpo da função; os comandos UNIX que devem ser executados quando se invoca a função. A chaveta de abertura e a chaveta de fecho devem ser colocadas no início da linha de modo a serem reconhecidas pela Shell como definindo o corpo da função.
Também foi discutido neste texto a criação de uma versão especial do editor de linha ed, que invoca sempre o editor com uma prompt. Para este caso a função teria o seguinte aspecto:
ed ()
{
ed -p '*' $* < &0
}
A escrita, no terminal, desta função ocorre facilmente; ao prompt $ inicia-se a escrita da função indicando o nome e os parentesis, pelo se obtem, de modo automático, a prompt secundária do sistema (normalmente o simbolo ">"). O diálogo terá a forma:
$ ed ()
> {
> ed -p '*' $* < &0
> }
$
Após indicar a chaveta de fecho, o sistema retorna à prompt $ indicando o fim da definição da função.
Se se definir esta função, esta apenas se encontra activa na sessão corrente UNIX e desaparece quando se sai do sistema (logout). Se se pretender a criação de funções permanentes, estas deverão estar contidas no ficheiro .profile; ficheiro de perfil.
É possível utilizar uma função shell dentro de um procedimento shell. Um exemplo é a nova versão do procedimento projetese:
proximofich () # extrai proximo ficheiro, eliminando-o na linha
{
fich =`echo $1`
shift
linha =`echo $*`
}
echo "De o nome do ficheiro, um por linha\n"
while true
do
echo "? \c"
read linha # obter outro nome de ficheiro
if test "$linha" = "."
then break # acabar se existir um ponto
fi
while test "$linha" = "" # ignorar linhas em branco
do
proximofich $linha
if test ! -s $linha # verificar existencia do ficheiro
then echo nao existe ficheiro $linha
else admin -fi -i$fich /usr/luis/tese/s.$fich
fi
done
done
O primeiro passo foi definir a função, proximofich, que apenas extrai o próximo nome do ficheiro da linha. O corpo principal do procedimento começa, como anteriormente, com o ciclo while true. Dentro deste ciclo existe um segundo que chama a função proximofich até a linha estar vazia.
As mensagens de erro produzidas pelo comando sh são bastante explícitas e constituem uma ajuda preciosa na procura e correção de erros de sintaxe num procedimento shell.
No entanto, existem outras ajudas para depurar e verificar os procedimentos shell. Uma é o uso do comando echo para imprimir mensagens de traçagem do procedimento; quando se concluiu que o procedimento está correcto essas mensagens são retiradas; designamos este processo por técnica de auto ajuda ou impressão estratégica.
Existem tambem argumentos fornecidos ao comando sh que são úteis na traçagem de procedimentos. A opção -v (verbose) indica ao Shell que deve imprimir os comandos antes de os executar. Assim, se se usar esta facilidade no procedimento para cálculo do resultado medio (procedimento resultmedio), obtêm-se:
$ sh -v resultmedio tennis
numero=`wc -l < $1`
total=0
contar=$numero
while test $contar -gt 0
do resultado=`sed -n ${contar}p $1 | tr -dc '[0-9]'`
total=`expr $total + $resultado`
contar=`expr $contar - 1`
done
resinteiro=`expr $total / $numero`
resdecimal=`expr $total % $numero \* 100`
echo Resultado medio: $resinteiro.$resdecimal
8.900
$
Trata-se apenas de uma listagem do procedimento. Todo o seu conteúdo até à palavra chave "done" é impresso, então dá-se uma pausa enquanto o total é calculado.
Uma facilidade de traçagem melhor é a opção -x (execute). Quando se utiliza esta opção cada comando é impresso, com visualização de todas as substituições de variáveis, assim que forem sendo executados os respectivos comandos.
O output da traçagem do procedimento tem o seguinte aspecto:
$ sh -x resultmedio tennis
+ wc -l
numero= 10
total=0
contar= 10
+ test 10 -gt 0
+ tr -dc [0-9]
+ sed -n 10p tennis
resultado=2
+ expr 0 + 2
total=2
+ expr 10 - 1
contar=9
+ test 9 -gt 0
........
< assim sucessivamente no ciclo >
........
+ test 1 -gt 0
+ tr -dc [0-9]
+ sed -n 1p tennis
resultado=18
+ expr 71 + 18
total=89
+ expr 1 - 1
contar=0
+ test 0 -gt 0
+ expr 89 / 10
resinteiro=8
+ expr 89 % 10 * 100
resdecimal=900
+ echo Resultado medio: 8.900
$
Cada comando aparece na linha assinalada com o simbolo "+" no seu início. Os valores das variáveis usadas no comando são visualizadas. Após cada comando ser executado, os valores das variáveis afectadas são impressos. Esta facilidade permite realmente verificar o que acontece no procedimento.
Se existir a possibilidade de danificar ou destruir ficheiros importantes enquanto se realiza a correção de erros, é possível usar a opção -n. A Shell lê os comandos do procedimento shell, mas não os executa. Esta opção pode ser usada em conjunção com a opção -x.
O presente texto procurou demonstrar, através de exemplos, as características gerais proporcionadas pelo Shell (Bourne Shell - sh) do sistema operativo UNIX. Existem bastante mais facilidades e formas de uso da Shell, mas no geral está aqui representada a maior parte e o mais importante deste. Com base neste texto deve-se tentar o desenvolvimento de outros procedimentos shell para as tarefas que mais normalmente se executam. Por exemplo, experimentar as diversas potencialidades do comando test.
A maioria dos utilizadores não terão necessidade de escrever procedimentos shell tão complexos como os apresentados, mas mesmo para estes fica demonstrado que é possível o desenho de ferramentas sofisticadas para tarefas especializadas. Os responsáveis pelos sistemas informáticos devem e tem de estar ao corrente destas facilidades.
A consulta do manual de referência dos comandos do sistema UNIX é importante, prestando atenção às opções possíveis para cada um; muitas destas parecem, quando pensadas em modo interativo de comando de linha, inúteis ou demasiado complicadas. Mas quando encaradas na perspectiva de uma eventual utilização em procedimentos shell, então transformam-se em poderosas e maravilhosas ferramentas.
Página criada a 17 de Junho de 1997 para a Web
Comentários para lmbg@ufp.pt